Добрый день, меня зовут Наталия Ефремова, и я research scientist в компании NtechLab. Сегодня я буду рассказывать про виды нейронных сетей и их применение.
Сначала скажу пару слов о нашей компании. Компания новая, может быть многие из вас еще не знают, чем мы занимаемся. В прошлом году мы выиграли состязание MegaFace . Это международное состязание по распознаванию лиц. В этом же году была открыта наша компания, то есть мы на рынке уже около года, даже чуть больше. Соответственно, мы одна из лидирующих компаний в распознавании лиц и обработке биометрических изображений.
Первая часть моего доклада будет направлена тем, кто незнаком с нейронными сетями. Я занимаюсь непосредственно deep learning. В этой области я работаю более 10 лет. Хотя она появилась чуть меньше, чем десятилетие назад, раньше были некие зачатки нейронных сетей, которые были похожи на систему deep learning.
В последние 10 лет deep learning и компьютерное зрение развивались неимоверными темпами. Все, что сделано значимого в этой области, произошло в последние лет 6.
Я расскажу о практических аспектах: где, когда, что применять в плане deep learning для обработки изображений и видео, для распознавания образов и лиц, поскольку я работаю в компании, которая этим занимается. Немножко расскажу про распознавание эмоций, какие подходы используются в играх и робототехнике. Также я расскажу про нестандартное применение deep learning, то, что только выходит из научных институтов и пока что еще мало применяется на практике, как это может применяться, и почему это сложно применить.
Доклад будет состоять из двух частей. Так как большинство знакомы с нейронными сетями, сначала я быстро расскажу, как работают нейронные сети, что такое биологические нейронные сети, почему нам важно знать, как это работает, что такое искусственные нейронные сети, и какие архитектуры в каких областях применяются.
Сразу извиняюсь, я буду немного перескакивать на английскую терминологию, потому что большую часть того, как называется это на русском языке, я даже не знаю. Возможно вы тоже.
Итак, первая часть доклада будет посвящена сверточным нейронным сетям. Я расскажу, как работают convolutional neural network (CNN), распознавание изображений на примере из распознавания лиц. Немного расскажу про рекуррентные нейронные сети recurrent neural network (RNN) и обучение с подкреплением на примере систем deep learning.
В качестве нестандартного применения нейронных сетей я расскажу о том, как CNN работает в медицине для распознавания воксельных изображений, как используются нейронные сети для распознавания бедности в Африке.
Что такое нейронные сети
Прототипом для создания нейронных сетей послужили, как это ни странно, биологические нейронные сети. Возможно, многие из вас знают, как программировать нейронную сеть, но откуда она взялась, я думаю, некоторые не знают. Две трети всей сенсорной информации, которая к нам попадает, приходит с зрительных органов восприятия. Более одной трети поверхности нашего мозга заняты двумя самыми главными зрительными зонами - дорсальный зрительный путь и вентральный зрительный путь.Дорсальный зрительный путь начинается в первичной зрительной зоне, в нашем темечке и продолжается наверх, в то время как вентральный путь начинается на нашем затылке и заканчивается примерно за ушами. Все важное распознавание образов, которое у нас происходит, все смыслонесущее, то что мы осознаём, проходит именно там же, за ушами.
Почему это важно? Потому что часто нужно для понимания нейронных сетей. Во-первых, все об этом рассказывают, и я уже привыкла что так происходит, а во-вторых, дело в том, что все области, которые используются в нейронных сетях для распознавания образов, пришли к нам именно из вентрального зрительного пути, где каждая маленькая зона отвечает за свою строго определенную функцию.
Изображение попадает к нам из сетчатки глаза, проходит череду зрительных зон и заканчивается в височной зоне.
В далекие 60-е годы прошлого века, когда только начиналось изучение зрительных зон мозга, первые эксперименты проводились на животных, потому что не было fMRI. Исследовали мозг с помощью электродов, вживлённых в различные зрительные зоны.
Первая зрительная зона была исследована Дэвидом Хьюбелем и Торстеном Визелем в 1962 году. Они проводили эксперименты на кошках. Кошкам показывались различные движущиеся объекты. На что реагировали клетки мозга, то и было тем стимулом, которое распознавало животное. Даже сейчас многие эксперименты проводятся этими драконовскими способами. Но тем не менее это самый эффективный способ узнать, что делает каждая мельчайшая клеточка в нашем мозгу.
Таким же способом были открыты еще многие важные свойства зрительных зон, которые мы используем в deep learning сейчас. Одно из важнейших свойств - это увеличение рецептивных полей наших клеток по мере продвижения от первичных зрительных зон к височным долям, то есть более поздним зрительным зонам. Рецептивное поле - это та часть изображения, которую обрабатывает каждая клеточка нашего мозга. У каждой клетки своё рецептивное поле. Это же свойство сохраняется и в нейронных сетях, как вы, наверное, все знаете.
Также с возрастанием рецептивных полей увеличиваются сложные стимулы, которые обычно распознают нейронные сети.

Здесь вы видите примеры сложности стимулов, различных двухмерных форм, которые распознаются в зонах V2, V4 и различных частях височных полей у макак. Также проводятся некоторое количество экспериментов на МРТ.

Здесь вы видите, как проводятся такие эксперименты. Это 1 нанометровая часть зон IT cortex"a мартышки при распознавании различных объектов. Подсвечено то, где распознается.
Просуммируем. Важное свойство, которое мы хотим перенять у зрительных зон - это то, что возрастают размеры рецептивных полей, и увеличивается сложность объектов, которые мы распознаем.
Компьютерное зрение
До того, как мы научились это применять к компьютерному зрению - в общем, как такового его не было. Во всяком случае, оно работало не так хорошо, как работает сейчас.Все эти свойства мы переносим в нейронную сеть, и вот оно заработало, если не включать небольшое отступление к датасетам, о котором расскажу попозже.
Но сначала немного о простейшем перцептроне. Он также образован по образу и подобию нашего мозга. Простейший элемент напоминающий клетку мозга - нейрон. Имеет входные элементы, которые по умолчанию располагаются слева направо, изредка снизу вверх. Слева это входные части нейрона, справа выходные части нейрона.
Простейший перцептрон способен выполнять только самые простые операции. Для того, чтобы выполнять более сложные вычисления, нам нужна структура с большим количеством скрытых слоёв.

В случае компьютерного зрения нам нужно еще больше скрытых слоёв. И только тогда система будет осмысленно распознавать то, что она видит.
Итак, что происходит при распознавании изображения, я расскажу на примере лиц.
Для нас посмотреть на эту картинку и сказать, что на ней изображено именно лицо статуи, достаточно просто. Однако до 2010 года для компьютерного зрения это было невероятно сложной задачей. Те, кто занимался этим вопросом до этого времени, наверное, знают насколько тяжело было описать объект, который мы хотим найти на картинке без слов.
Нам нужно это было сделать каким-то геометрическим способом, описать объект, описать взаимосвязи объекта, как могут эти части относиться к друг другу, потом найти это изображение на объекте, сравнить их и получить, что мы распознали плохо. Обычно это было чуть лучше, чем подбрасывание монетки. Чуть лучше, чем chance level.
Сейчас это происходит не так. Мы разбиваем наше изображение либо на пиксели, либо на некие патчи: 2х2, 3х3, 5х5, 11х11 пикселей - как удобно создателям системы, в которой они служат входным слоем в нейронную сеть.
Сигналы с этих входных слоёв передаются от слоя к слою с помощью синапсов, каждый из слоёв имеет свои определенные коэффициенты. Итак, мы передаём от слоя к слою, от слоя к слою, пока мы не получим, что мы распознали лицо.
Условно все эти части можно разделить на три класса, мы их обозначим X, W и Y, где Х - это наше входное изображение, Y - это набор лейблов, и нам нужно получить наши веса. Как мы вычислим W?
При наличии нашего Х и Y это, кажется, просто. Однако то, что обозначено звездочкой, очень сложная нелинейная операция, которая, к сожалению, не имеет обратной. Даже имея 2 заданных компоненты уравнения, очень сложно ее вычислить. Поэтому нам нужно постепенно, методом проб и ошибок, подбором веса W сделать так, чтобы ошибка максимально уменьшилась, желательно, чтобы стала равной нулю.

Этот процесс происходит итеративно, мы постоянно уменьшаем, пока не находим то значение веса W, которое нас достаточно устроит.
К слову, ни одна нейронная сеть, с которой я работала, не достигала ошибки, равной нулю, но работала при этом достаточно хорошо.

Перед вами первая сеть, которая победила на международном соревновании ImageNet в 2012 году. Это так называемый AlexNet. Это сеть, которая впервые заявила о себе, о том, что существует convolutional neural networks и с тех самых пор на всех международных состязаниях уже convolutional neural nets не сдавали своих позиций никогда.
Несмотря на то, что эта сеть достаточно мелкая (в ней всего 7 скрытых слоёв), она содержит 650 тысяч нейронов с 60 миллионами параметров. Для того, чтобы итеративно научиться находить нужные веса, нам нужно очень много примеров.
Нейронная сеть учится на примере картинки и лейбла. Как нас в детстве учат «это кошка, а это собака», так же нейронные сети обучаются на большом количестве картинок. Но дело в том, что до 2010 не существовало достаточно большого data set’a, который способен был бы научить такое количество параметров распознавать изображения.
Самые большие базы данных, которые существовали до этого времени: PASCAL VOC, в который было всего 20 категорий объектов, и Caltech 101, который был разработан в California Institute of Technology. В последнем была 101 категория, и это было много. Тем же, кто не сумел найти свои объекты ни в одной из этих баз данных, приходилось стоить свои базы данных, что, я скажу, страшно мучительно.
Однако, в 2010 году появилась база ImageNet, в которой было 15 миллионов изображений, разделённые на 22 тысячи категорий. Это решило нашу проблему обучения нейронных сетей. Сейчас все желающие, у кого есть какой-либо академический адрес, могут спокойно зайти на сайт базы, запросить доступ и получить эту базу для тренировки своих нейронных сетей. Они отвечают достаточно быстро, по-моему, на следующий день.
По сравнению с предыдущими data set’ами, это очень большая база данных.

На примере видно, насколько было незначительно все то, что было до неё. Одновременно с базой ImageNet появилось соревнование ImageNet, международный challenge, в котором все команды, желающие посоревноваться, могут принять участие.
В этом году победила сеть, созданная в Китае, в ней было 269 слоёв. Не знаю, сколько параметров, подозреваю, тоже много.
Архитектура глубинной нейронной сети
Условно ее можно разделить на 2 части: те, которые учатся, и те, которые не учатся.
Чёрным обозначены те части, которые не учатся, все остальные слои способны обучаться. Существует множество определений того, что находится внутри каждого сверточного слоя. Одно из принятых обозначений - один слой с тремя компонентами разделяют на convolution stage, detector stage и pooling stage.
Не буду вдаваться в детали, еще будет много докладов, в которых подробно рассмотрено, как это работает. Расскажу на примере.
Поскольку организаторы просили меня не упоминать много формул, я их выкинула совсем.

Итак, входное изображение попадает в сеть слоёв, которые можно назвать фильтрами разного размера и разной сложности элементов, которые они распознают. Эти фильтры составляют некий свой индекс или набор признаков, который потом попадает в классификатор. Обычно это либо SVM, либо MLP - многослойный перцептрон, кому что удобно.
По образу и подобию с биологической нейронной сетью объекты распознаются разной сложности. По мере увеличения количества слоёв это все потеряло связь с cortex’ом, поскольку там ограничено количество зон в нейронной сети. 269 или много-много зон абстракции, поэтому сохраняется только увеличение сложности, количества элементов и рецептивных полей.

Если рассмотреть на примере распознавания лиц, то у нас рецептивное поле первого слоя будет маленьким, потом чуть побольше, побольше, и так до тех пор, пока наконец мы не сможем распознавать уже лицо целиком.

С точки зрения того, что находится у нас внутри фильтров, сначала будут наклонные палочки плюс немного цвета, затем части лиц, а потом уже целиком лица будут распознаваться каждой клеточкой слоя.
Есть люди, которые утверждают, что человек всегда распознаёт лучше, чем сеть. Так ли это?
В 2014 году ученые решили проверить, насколько мы хорошо распознаем в сравнении с нейронными сетями. Они взяли 2 самые лучшие на данный момент сети - это AlexNet и сеть Мэттью Зиллера и Фергюса, и сравнили с откликом разных зон мозга макаки, которая тоже была научена распознавать какие-то объекты. Объекты были из животного мира, чтобы обезьяна не запуталась, и были проведены эксперименты, кто же распознаёт лучше.
Так как получить отклик от мартышки внятно невозможно, ей вживили электроды и мерили непосредственно отклик каждого нейрона.
Оказалось, что в нормальных условиях клетки мозга реагировали так же хорошо, как и state of the art model на тот момент, то есть сеть Мэттью Зиллера.
Однако при увеличении скорости показа объектов, увеличении количества шумов и объектов на изображении скорость распознавания и его качество нашего мозга и мозга приматов сильно падают. Даже самая простая сверточная нейронная сеть распознаёт объекты лучше. То есть официально нейронные сети работают лучше, чем наш мозг.
Классические задачи сверточных нейронных сетей
Их на самом деле не так много, они относятся к трём классам. Среди них - такие задачи, как идентификация объекта, семантическая сегментация, распознавание лиц, распознавание частей тела человека, семантическое определение границ, выделение объектов внимания на изображении и выделение нормалей к поверхности. Их условно можно разделить на 3 уровня: от самых низкоуровневых задач до самых высокоуровневых задач.
На примере этого изображения рассмотрим, что делает каждая из задач.
- Определение границ - это самая низкоуровневая задача, для которой уже классически применяются сверточные нейронные сети.
- Определение вектора к нормали позволяет нам реконструировать трёхмерное изображение из двухмерного.
- Saliency, определение объектов внимания - это то, на что обратил бы внимание человек при рассмотрении этой картинки.
- Семантическая сегментация позволяет разделить объекты на классы по их структуре, ничего не зная об этих объектах, то есть еще до их распознавания.
- Семантическое выделение границ - это выделение границ, разбитых на классы.
- Выделение частей тела человека .
- И самая высокоуровневая задача - распознавание самих объектов , которое мы сейчас рассмотрим на примере распознавания лиц.
Распознавание лиц
Первое, что мы делаем - пробегаем face detector"ом по изображению для того, чтобы найти лицо. Далее мы нормализуем, центрируем лицо и запускаем его на обработку в нейронную сеть. После чего получаем набор или вектор признаков однозначно описывающий фичи этого лица.
Затем мы можем этот вектор признаков сравнить со всеми векторами признаков, которые хранятся у нас в базе данных, и получить отсылку на конкретного человека, на его имя, на его профиль - всё, что у нас может храниться в базе данных.
Именно таким образом работает наш продукт FindFace - это бесплатный сервис, который помогает искать профили людей в базе «ВКонтакте».
Кроме того, у нас есть API для компаний, которые хотят попробовать наши продукты. Мы предоставляем сервис по детектированию лиц, по верификации и по идентификации пользователей.
Сейчас у нас разработаны 2 сценария. Первый - это идентификация, поиск лица по базе данных. Второе - это верификация, это сравнение двух изображений с некой вероятностью, что это один и тот же человек. Кроме того, у нас сейчас в разработке распознавание эмоций, распознавание изображений на видео и liveness detection - это понимание, живой ли человек перед камерой или фотография.
Немного статистики. При идентификации, при поиске по 10 тысячам фото у нас точность около 95% в зависимости от качества базы, 99% точность верификации. И помимо этого данный алгоритм очень устойчив к изменениям - нам необязательно смотреть в камеру, у нас могут быть некие загораживающие предметы: очки, солнечные очки, борода, медицинская маска. В некоторых случаях мы можем победить даже такие невероятные сложности для компьютерного зрения, как и очки, и маска.
Очень быстрый поиск, затрачивается 0,5 секунд на обработку 1 миллиарда фотографий. Нами разработан уникальный индекс быстрого поиска. Также мы можем работать с изображениями низкого качества, полученных с CCTV-камер. Мы можем обрабатывать это все в режиме реального времени. Можно загружать фото через веб-интерфейс, через Android, iOS и производить поиск по 100 миллионам пользователей и их 250 миллионам фотографий.
Как я уже говорила мы заняли первое место на MegaFace competition - аналог для ImageNet, но для распознавания лиц. Он проводится уже несколько лет, в прошлом году мы были лучшими среди 100 команд со всего мира, включая Google.
Рекуррентные нейронные сети
Recurrent neural networks мы используем тогда, когда нам недостаточно распознавать только изображение. В тех случаях, когда нам важно соблюдать последовательность, нам нужен порядок того, что у нас происходит, мы используем обычные рекуррентные нейронные сети.Это применяется для распознавания естественного языка, для обработки видео, даже используется для распознавания изображений.
Про распознавание естественного языка я рассказывать не буду - после моего доклада еще будут два, которые будут направлены на распознавание естественного языка. Поэтому я расскажу про работу рекуррентных сетей на примере распознавания эмоций.
Что такое рекуррентные нейронные сети? Это примерно то же самое, что и обычные нейронные сети, но с обратной связью. Обратная связь нам нужна, чтобы передавать на вход нейронной сети или на какой-то из ее слоев предыдущее состояние системы.
Предположим, мы обрабатываем эмоции. Даже в улыбке - одной из самых простых эмоций - есть несколько моментов: от нейтрального выражения лица до того момента, когда у нас будет полная улыбка. Они идут друг за другом последовательно. Чтоб это хорошо понимать, нам нужно уметь наблюдать за тем, как это происходит, передавать то, что было на предыдущем кадре в следующий шаг работы системы.

В 2005 году на состязании Emotion Recognition in the Wild специально для распознавания эмоций команда из Монреаля представила рекуррентную систему, которая выглядела очень просто. У нее было всего несколько свёрточных слоев, и она работала исключительно с видео. В этом году они добавили также распознавание аудио и cагрегировали покадровые данные, которые получаются из convolutional neural networks, данные аудиосигнала с работой рекуррентной нейронной сети (с возвратом состояния) и получили первое место на состязании.
Обучение с подкреплением
Следующий тип нейронных сетей, который очень часто используется в последнее время, но не получил такой широкой огласки, как предыдущие 2 типа - это deep reinforcement learning, обучение с подкреплением.Дело в том, что в предыдущих двух случаях мы используем базы данных. У нас есть либо данные с лиц, либо данные с картинок, либо данные с эмоциями с видеороликов. Если у нас этого нет, если мы не можем это отснять, как научить робота брать объекты? Это мы делаем автоматически - мы не знаем, как это работает. Другой пример: составлять большие базы данных в компьютерных играх сложно, да и не нужно, можно сделать гораздо проще.
Все, наверное, слышали про успехи deep reinforcement learning в Atari и в го.
Кто слышал про Atari? Ну кто-то слышал, хорошо. Про AlphaGo думаю слышали все, поэтому я даже не буду рассказывать, что конкретно там происходит.

Что происходит в Atari? Слева как раз изображена архитектура этой нейронной сети. Она обучается, играя сама с собой для того, чтобы получить максимальное вознаграждение. Максимальное вознаграждение - это максимально быстрый исход игры с максимально большим счетом.
Справа вверху - последний слой нейронной сети, который изображает всё количество состояний системы, которая играла сама против себя всего лишь в течение двух часов. Красным изображены желательные исходы игры с максимальным вознаграждением, а голубым - нежелательные. Сеть строит некое поле и движется по своим обученным слоям в то состояние, которого ей хочется достичь.
В робототехнике ситуация состоит немного по-другому. Почему? Здесь у нас есть несколько сложностей. Во-первых, у нас не так много баз данных. Во-вторых, нам нужно координировать сразу три системы: восприятие робота, его действия с помощью манипуляторов и его память - то, что было сделано в предыдущем шаге и как это было сделано. В общем это все очень сложно.
Дело в том, что ни одна нейронная сеть, даже deep learning на данный момент, не может справится с этой задачей достаточно эффективно, поэтому deep learning только исключительно кусочки того, что нужно сделать роботам. Например, недавно Сергей Левин предоставил систему, которая учит робота хватать объекты.

Вот здесь показаны опыты, которые он проводил на своих 14 роботах-манипуляторах.
Что здесь происходит? В этих тазиках, которые вы перед собой видите, различные объекты: ручки, ластики, кружки поменьше и побольше, тряпочки, разные текстуры, разной жесткости. Неясно, как научить робота захватывать их. В течение многих часов, а даже, вроде, недель, роботы тренировались, чтобы уметь захватывать эти предметы, составлялись по этому поводу базы данных.
Базы данных - это некий отклик среды, который нам нужно накопить для того, чтобы иметь возможность обучить робота что-то делать в дальнейшем. В дальнейшем роботы будут обучаться на этом множестве состояний системы.
Нестандартные применения нейронных сетей
Это к сожалению, конец, у меня не много времени. Я расскажу про те нестандартные решения, которые сейчас есть и которые, по многим прогнозам, будут иметь некое приложение в будущем.Итак, ученые Стэнфорда недавно придумали очень необычное применение нейронной сети CNN для предсказания бедности. Что они сделали?
На самом деле концепция очень проста. Дело в том, что в Африке уровень бедности зашкаливает за все мыслимые и немыслимые пределы. У них нет даже возможности собирать социальные демографические данные. Поэтому с 2005 года у нас вообще нет никаких данных о том, что там происходит.
Учёные собирали дневные и ночные карты со спутников и скармливали их нейронной сети в течение некоторого времени.
Нейронная сеть была преднастроена на ImageNet"е. То есть первые слои фильтров были настроены так, чтобы она умела распознавать уже какие-то совсем простые вещи, например, крыши домов, для поиска поселения на дневных картах. Затем дневные карты были сопоставлены с картами ночной освещенности того же участка поверхности для того, чтобы сказать, насколько есть деньги у населения, чтобы хотя бы освещать свои дома в течение ночного времени.

Здесь вы видите результаты прогноза, построенного нейронной сетью. Прогноз был сделан с различным разрешением. И вы видите - самый последний кадр - реальные данные, собранные правительством Уганды в 2005 году.
Можно заметить, что нейронная сеть составила достаточно точный прогноз, даже с небольшим сдвигом с 2005 года.
Были конечно и побочные эффекты. Ученые, которые занимаются deep learning, всегда с удивлением обнаруживают разные побочные эффекты. Например, как те, что сеть научилась распознавать воду, леса, крупные строительные объекты, дороги - все это без учителей, без заранее построенных баз данных. Вообще полностью самостоятельно. Были некие слои, которые реагировали, например, на дороги.
И последнее применение о котором я хотела бы поговорить - семантическая сегментация 3D изображений в медицине. Вообще medical imaging - это сложная область, с которой очень сложно работать.
Для этого есть несколько причин.
- У нас очень мало баз данных. Не так легко найти картинку мозга, к тому же повреждённого, и взять ее тоже ниоткуда нельзя.
- Даже если у нас есть такая картинка, нужно взять медика и заставить его вручную размещать все многослойные изображения, что очень долго и крайне неэффективно. Не все медики имеют ресурсы для того, чтобы этим заниматься.
- Нужна очень высокая точность. Медицинская система не может ошибаться. При распознавании, например, котиков, не распознали - ничего страшного. А если мы не распознали опухоль, то это уже не очень хорошо. Здесь особо свирепые требования к надежности системы.
- Изображения в трехмерных элементах - вокселях, не в пикселях, что доставляет дополнительные сложности разработчикам систем.
Где это применяется: определение повреждений после удара, для поиска опухоли в мозгу, в кардиологии для определения того, как работает сердце.

Вот пример для определения объема плаценты.
Автоматически это работает хорошо, но не настолько, чтобы это было выпущено в производство, поэтому пока только начинается. Есть несколько стартапов для создания таких систем медицинского зрения. Вообще в deep learning очень много стартапов в ближайшее время. Говорят, что venture capitalists в последние полгода выделили больше бюджета на стартапы обрасти deep learning, чем за прошедшие 5 лет.
Эта область активно развивается, много интересных направлений. Мы с вами живем в интересное время. Если вы занимаетесь deep learning, то вам, наверное, пора открывать свой стартап.
Ну на этом я, наверное, закруглюсь. Спасибо вам большое.
Правильная постановка вопроса должна быть такой: как натренировать сою собственную нейросеть? Писать сеть самому не нужно, нужно взять какую-то из готовых реализаций, которых есть множество, предыдущие авторы давали ссылки. Но сама по себе эта реализация подобна компьютеру, в который не закачали никаких программ. Для того, чтобы сеть решала вашу задачу, ее нужно научить.
И тут возникает собственно самое важное, что вам для этого потребуется: ДАННЫЕ. Много примеров задач, которые будут подаваться на вход нейросети, и правильные ответы на эти задачи. Нейросеть будет на этом учиться самостоятельно давать эти правильные ответы.
И вот тут возникает куча деталей и нюансов, которые нужно знать и понимать, чтобы это все имело шанс дать приемлемый результат. Осветить их все здесь нереально, поэтому просто перечислю некоторые пункты. Во-первых, объем данных. Это очень важный момент. Крупные компании, деятельность которых связана с машинным обучением, обычно содержат специальные отделы и штат сотрудников, занимающихся только сбором и обработкой данных для обучения нейросетей. Нередко данные приходится покупать, и вся эта деятельность выливается в заметную статью расходов. Во-вторых, представление данных. Если каждый объект в вашей задаче представлен относительно небольшим числом числовых параметров, то есть шанс, что их можно прямо в таком сыром виде дать нейросети, и получить приемлемый результат на выходе. Но если объекты сложные (картинки, звук, объекты переменной размерности), то скорее всего придется потратить время и силы на выделение из них содержательных для решаемой задачи признаков. Одно только это может занять очень много времени и иметь гораздо более влияние на итоговый результат, чем даже вид и архитектура выбранной для использования нейросети.
Нередки случаи, когда реальные данные оказываются слишком сырыми и непригодными для использования без предварительной обработки: содержат пропуски, шумы, противоречия и ошибки.
Данные должны быть собраны тоже не абы как, а грамотно и продуманно. Иначе обученная сеть может вести себя странно и даже решать совсем не ту задачу, которую предполагал автор.
Также нужно представлять себе, как грамотно организовать процесс обучения, чтобы сеть не оказалась переученной. Сложность сети нужно выбирать исходя из размерности данных и их количества. Часть данных нужно отложить для теста и при обучении не использовать, чтобы оценить реальное качество работы. Иногда различным объектам из обучающего множества нужно приписать различный вес. Иногда эти веса полезно варьировать в процессе обучения. Иногда полезно начинать обучение на части данных, а по мере обучения добавлять оставшиеся данные. В общем, это можно сравнить с кулинарией: у каждой хозяйки свои приемы готовки даже одинаковых блюд.
В данной статье собраны материалы - в основном русскоязычные - для базового изучения искусственных нейронных сетей.
Искусственная нейронная сеть, или ИНС - математическая модель, а также ее программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей - сетей нервных клеток живого организма. Наука нейронных сетей существует достаточно давно, однако именно в связи с последними достижениями научно-технического прогресса данная область начинает обретать популярность.
Книги
Начнем подборку с классического способа изучения - с помощью книг. Мы подобрали русскоязычные книги с большим количеством примеров:
- Ф. Уоссермен, Нейрокомпьютерная техника: Теория и практика. 1992 г.
В книге в общедоступной форме излагаются основы построения нейрокомпьютеров. Описана структура нейронных сетей и различные алгоритмы их настройки. Отдельные главы посвящены вопросам реализации нейронных сетей. - С. Хайкин, Нейронные сети: Полный курс. 2006 г.
Здесь рассматриваются основные парадигмы искусственных нейронных сетей. Представленный материал содержит строгое математическое обоснование всех нейросетевых парадигм, иллюстрируется примерами, описанием компьютерных экспериментов, содержит множество практических задач, а также обширную библиографию.
Д. Форсайт, Компьютерное зрение. Современный подход. 2004 г.
Компьютерное зрение – это одна из самых востребованных областей на данном этапе развития глобальных цифровых компьютерных технологий. Оно требуется на производстве, при управлении роботами, при автоматизации процессов, в медицинских и военных приложениях, при наблюдении со спутников и при работе с персональными компьютерами, в частности, поиске цифровых изображений.
Видео
Нет ничего доступнее и понятнее, чем визуальное обучение при помощи видео:
- Чтобы понять,что такое вообще машинное обучение, посмотрите вот эти две лекции от ШАДа Яндекса.
- Введение в основные принципы проектирования нейронных сетей - отлично подходит для продолжения знакомства с нейронными сетями.
- Курс лекций по теме «Компьютерное зрение» от ВМК МГУ. Компьютерное зрение - теория и технология создания искусственных систем, которые производят обнаружение и классификацию объектов в изображениях и видеозаписях. Эти лекции можно отнести к введению в эту интересную и сложную науку.
Образовательные ресурсы и полезные ссылки
- Портал искусственного интеллекта.
- Лаборатория «Я - интеллект».
- Нейронные сети в Matlab .
- Нейронные сети в Python (англ.):
- Классификация текста с помощью ;
- Простой .
- Нейронная сеть на .
Серия наших публикаций по теме
Ранее у нас публиковался уже курс #neuralnetwork@tproger по нейронным сетям. В этом списке публикации для вашего удобства расположены в порядке изучения.
Многие из терминов в нейронных сетях связаны с биологией, поэтому давайте начнем с самого начала:
Мозг - штука сложная, но и его можно разделить на несколько основных частей и операций:

Возбудитель может быть и внутренним (например, образ или идея):

А теперь взглянем на основные и упрощенные части мозга:

Мозг вообще похож на кабельную сеть.
Нейрон - основная единица исчислений в мозге, он получает и обрабатывает химические сигналы других нейронов, и, в зависимости от ряда факторов, либо не делает ничего, либо генерирует электрический импульс, или Потенциал Действия, который затем через синапсы подает сигналы соседним связанным нейронам:

Сны, воспоминания, саморегулируемые движения, рефлексы да и вообще все, что вы думаете или делаете - все происходит благодаря этому процессу: миллионы, или даже миллиарды нейронов работают на разных уровнях и создают связи, которые создают различные параллельные подсистемы и представляют собой биологическую нейронную сеть .
Разумеется, это всё упрощения и обобщения, но благодаря им мы можем описать простую
нейронную сеть:

И описать её формализовано с помощью графа:

Тут требуются некоторые пояснения. Кружки - это нейроны, а линии - это связи между ними,
и, чтобы не усложнять на этом этапе, взаимосвязи
представляют собой прямое передвижение информации слева направо
. Первый нейрон в данный момент активен и выделен серым. Также мы присвоили ему число (1 - если он работает, 0 - если нет). Числа между нейронами показывают вес
связи.
Графы выше показывают момент времени сети, для более точного отображения, нужно разделить его на временные отрезки:

Для создания своей нейронной сети нужно понимать, как веса влияют на нейроны и как нейроны обучаются. В качестве примера возьмем кролика (тестового кролика) и поставим его в условия классического эксперимента.

Когда на них направляют безопасную струю воздуха, кролики, как и люди, моргают:

Эту модель поведения можно нарисовать графами:

Как и в предыдущей схеме, эти графы показывают только тот момент, когда кролик чувствует дуновение, и мы таким образом кодируем дуновение как логическое значение. Помимо этого мы вычисляем, срабатывает ли второй нейрон, основываясь на значении веса. Если он равен 1, то сенсорный нейрон срабатывает, мы моргаем; если вес меньше 1, мы не моргаем: у второго нейрона предел - 1.
Введем еще один элемент - безопасный звуковой сигнал:

Мы можем смоделировать заинтересованность кролика так:

Основное отличие в том, что сейчас вес равен нулю
, поэтому моргающего кролика мы не получили, ну, пока, по крайней мере. Теперь научим кролика моргать по команде, смешивая
раздражители (звуковой сигнал и дуновение):

Важно, что эти события происходят в разные временные эпохи , в графах это будет выглядеть так:

Сам по себе звук ничего не делает, но воздушный поток по-прежнему заставляет кролика моргать, и мы показываем это через веса, умноженные на раздражители (красным).
Обучение сложному поведению можно упрощённо выразить как постепенное изменение веса между связанными нейронами с течением времени.
Чтобы обучить кролика, повторим действия:

Для первых трех попыток схемы будут выглядеть так:

Обратите внимание, что вес для звукового раздражителя растет после каждого повтора (выделено красным), это значение сейчас произвольное - мы выбрали 0.30, но число может быть каким угодно, даже отрицательным. После третьего повтора вы не заметите изменения в поведении кролика, но после четвертого повтора произойдет нечто удивительное - поведение изменится.

Мы убрали воздействие воздухом, но кролик все еще моргает, услышав звуковой сигнал! Объяснить это поведение может наша последняя схемка:

Мы обучили кролика реагировать на звук морганием.

В условиях реального эксперимента такого рода может потребоваться более 60 повторений для достижения результата.
Теперь мы оставим биологический мир мозга и кроликов и попробуем адаптировать всё, что
узнали, для создания искусственной нейросети. Для начала попробуем сделать простую задачу.
Допустим, у нас есть машина с четырьмя кнопками, которая выдает еду при нажатии правильной
кнопки (ну, или энергию, если вы робот). Задача - узнать, какая кнопка выдает вознаграждение:

Мы можем изобразить (схематично), что делает кнопка при нажатии следующим образом:

Такую задачу лучше решать целиком, поэтому давайте посмотрим на все возможные результаты, включая правильный:

Нажмите на 3-ю кнопку, чтобы получить свой ужин.
Чтобы воспроизвести нейронную сеть в коде, нам для начала нужно сделать модель или график, с которым можно сопоставить сеть. Вот один подходящий под задачу график, к тому же он хорошо отображает свой биологический аналог:

Эта нейронная сеть просто получает входящую информацию - в данном случае это будет восприятие того, какую кнопку нажали. Далее сеть заменяет входящую информацию на веса и делает вывод на основе добавления слоя. Звучит немного запутанно, но давайте посмотрим, как в нашей модели представлена кнопка:

Обратите внимание, что все веса равны 0, поэтому нейронная сеть, как младенец, совершенно пуста, но полностью взаимосвязана.
Таким образом мы сопоставляем внешнее событие с входным слоем нейронной сети и вычисляем значение на ее выходе. Оно может совпадать или не совпадать с реальностью, но это мы пока проигнорируем и начнем описывать задачу понятным компьютеру способом. Начнем с ввода весов (будем использовать JavaScript):
Var inputs = ;
var weights = ;
// Для удобства эти векторы можно назвать
Следующий шаг - создание функции, которая собирает входные значения и веса и рассчитывает значение на выходе:
Function evaluateNeuralNetwork(inputVector, weightVector){
var result = 0;
inputVector.forEach(function(inputValue, weightIndex) {
layerValue = inputValue*weightVector;
result += layerValue;
});
return (result.toFixed(2));
}
// Может казаться комплексной, но все, что она делает - это сопоставляет пары вес/ввод и добавляет результат
Как и ожидалось, если мы запустим этот код, то получим такой же результат, как в нашей модели или графике…
EvaluateNeuralNetwork(inputs, weights); // 0.00
Живой пример: Neural Net 001 .
Следующим шагом в усовершенствовании нашей нейросети будет способ проверки её собственных выходных или результирующих значений сопоставимо реальной ситуации,
давайте сначала закодируем эту конкретную реальность в переменную:

Чтобы обнаружить несоответствия (и сколько их), мы добавим функцию ошибки:
Error = Reality - Neural Net Output
С ней мы можем оценивать работу нашей нейронной сети:

Но что более важно - как насчет ситуаций, когда реальность дает положительный результат?

Теперь мы знаем, что наша модель нейронной сети не работает (и знаем, насколько), здорово! А здорово это потому, что теперь мы можем использовать функцию ошибки для управления нашим обучением. Но всё это обретет смысл в том случае, если мы переопределим функцию ошибок следующим образом:
Error = Desired Output - Neural Net Output
Неуловимое, но такое важное расхождение, молчаливо показывающее, что мы будем
использовать ранее полученные результаты для сопоставления с будущими действиями
(и для обучения, как мы потом увидим). Это существует и в реальной жизни, полной
повторяющихся паттернов, поэтому оно может стать эволюционной стратегией (ну, в
большинстве случаев).
Var input = ;
var weights = ;
var desiredResult = 1;
И новую функцию:
Function evaluateNeuralNetError(desired,actual) {
return (desired - actual);
}
// After evaluating both the Network and the Error we would get:
// "Neural Net output: 0.00 Error: 1"
Живой пример: Neural Net 002 .
Подведем промежуточный итог . Мы начали с задачи, сделали её простую модель в виде биологической нейронной сети и получили способ измерения её производительности по сравнению с реальностью или желаемым результатом. Теперь нам нужно найти способ исправления несоответствия - процесс, который как и для компьютеров, так и для людей можно рассматривать как обучение.
Как обучать нейронную сеть?
Основа обучения как биологической, так и искусственной нейронной сети - это повторение
и алгоритмы обучения
, поэтому мы будем работать с ними по отдельности. Начнем с
обучающих алгоритмов.
В природе под алгоритмами обучения понимаются изменения физических или химических
характеристик нейронов после проведения экспериментов:

Драматическая иллюстрация того, как два нейрона меняются по прошествии времени в коде и нашей модели «алгоритм обучения» означает, что мы просто будем что-то менять в течение какого-то времени, чтобы облегчить свою жизнь. Поэтому давайте добавим переменную для обозначения степени облегчения жизни:
Var learningRate = 0.20;
// Чем больше значение, тем быстрее будет процесс обучения:)
И что это изменит?
Это изменит веса (прям как у кролика!), особенно вес вывода, который мы хотим получить:

Как кодировать такой алгоритм - ваш выбор, я для простоты добавляю коэффициент обучения к весу, вот он в виде функции:
Function learn(inputVector, weightVector) {
weightVector.forEach(function(weight, index, weights) {
if (inputVector > 0) {
weights = weight + learningRate;
}
});
}
При использовании эта обучающая функция просто добавит наш коэффициент обучения к вектору веса активного нейрона
, до и после круга обучения (или повтора) результаты будут такими:
// Original weight vector:
// Neural Net output: 0.00 Error: 1
learn(input, weights);
// New Weight vector:
// Neural Net output: 0.20 Error: 0.8
// Если это не очевидно, вывод нейронной сети близок к 1 (выдача курицы) - то, чего мы и
хотели, поэтому можно сделать вывод, что мы движемся в правильном направлении
Живой пример: Neural Net 003 .
Окей, теперь, когда мы движемся в верном направлении, последней деталью этой головоломки будет внедрение повторов .
Это не так уж и сложно, в природе мы просто делаем одно и то же снова и снова, а в коде мы просто указываем количество повторов:
Var trials = 6;
И внедрение в нашу обучающую нейросеть функции количества повторов будет выглядеть так:
Function train(trials) {
for (i = 0; i < trials; i++) {
neuralNetResult = evaluateNeuralNetwork(input, weights);
learn(input, weights);
}
}
Ну и наш окончательный отчет:
Neural Net output: 0.00 Error: 1.00 Weight Vector:
Neural Net output: 0.20 Error: 0.80 Weight Vector:
Neural Net output: 0.40 Error: 0.60 Weight Vector:
Neural Net output: 0.60 Error: 0.40 Weight Vector:
Neural Net output: 0.80 Error: 0.20 Weight Vector:
Neural Net output: 1.00 Error: 0.00 Weight Vector:
// Chicken Dinner !
Живой пример: Neural Net 004 .
Теперь у нас есть вектор веса, который даст только один результат (курицу на ужин), если входной вектор соответствует реальности (нажатие на третью кнопку).
Так что же такое классное мы только что сделали?
В этом конкретном случае наша нейронная сеть (после обучения) может распознавать входные данные и говорить, что приведет к желаемому результату (нам всё равно нужно будет программировать конкретные ситуации):

Кроме того, это масштабируемая модель, игрушка и инструмент для нашего с вами обучения. Мы смогли узнать что-то новое о машинном обучении, нейронных сетях и искусственном интеллекте.
Предостережение пользователям:
- Механизм хранения изученных весов не предусмотрен, поэтому данная нейронная сеть забудет всё, что знает. При обновлении или повторном запуске кода нужно не менее шести успешных повторов, чтобы сеть полностью обучилась, если вы считаете, что человек или машина будут нажимать на кнопки в случайном порядке… Это займет какое-то время.
- Биологические сети для обучения важным вещам имеют скорость обучения 1, поэтому нужен будет только один успешный повтор.
- Существует алгоритм обучения, который очень напоминает биологические нейроны, у него броское название: правило widroff-hoff , или обучение widroff-hoff .
- Пороги нейронов (1 в нашем примере) и эффекты переобучения (при большом количестве повторов результат будет больше 1) не учитываются, но они очень важны в природе и отвечают за большие и сложные блоки поведенческих реакций. Как и отрицательные веса.
Заметки и список литературы для дальнейшего чтения
Я пытался избежать математики и строгих терминов, но если вам интересно, то мы построили перцептрон , который определяется как алгоритм контролируемого обучения (обучение с учителем) двойных классификаторов - тяжелая штука.Биологическое строение мозга - тема не простая, отчасти из-за неточности, отчасти из-за его сложности. Лучше начинать с Neuroscience (Purves) и Cognitive Neuroscience (Gazzaniga). Я изменил и адаптировал пример с кроликом из Gateway to Memory (Gluck), которая также является прекрасным проводником в мир графов.
Еще один шикарный ресурс An Introduction to Neural Networks (Gurney), подойдет для всех ваших нужд, связанных с ИИ.
А теперь на Python! Спасибо Илье Андшмидту за предоставленную версию на Python:
Inputs =
weights =
desired_result = 1
learning_rate = 0.2
trials = 6
def evaluate_neural_network(input_array, weight_array):
result = 0
for i in range(len(input_array)):
layer_value = input_array[i] * weight_array[i]
result += layer_value
print("evaluate_neural_network: " + str(result))
print("weights: " + str(weights))
return result
def evaluate_error(desired, actual):
error = desired - actual
print("evaluate_error: " + str(error))
return error
def learn(input_array, weight_array):
print("learning...")
for i in range(len(input_array)):
if input_array[i] > 0:
weight_array[i] += learning_rate
def train(trials):
for i in range(trials):
neural_net_result = evaluate_neural_network(inputs, weights)
learn(inputs, weights)
train(trials)
А теперь на GO! За эту версию благодарю Кирана Мэхера.
Package main import ("fmt" "math") func main() { fmt.Println("Creating inputs and weights ...") inputs:= float64{0.00, 0.00, 1.00, 0.00} weights:= float64{0.00, 0.00, 0.00, 0.00} desired:= 1.00 learningRate:= 0.20 trials:= 6 train(trials, inputs, weights, desired, learningRate) } func train(trials int, inputs float64, weights float64, desired float64, learningRate float64) { for i:= 1; i < trials; i++ { weights = learn(inputs, weights, learningRate) output:= evaluate(inputs, weights) errorResult:= evaluateError(desired, output) fmt.Print("Output: ") fmt.Print(math.Round(output*100) / 100) fmt.Print("\nError: ") fmt.Print(math.Round(errorResult*100) / 100) fmt.Print("\n\n") } } func learn(inputVector float64, weightVector float64, learningRate float64) float64 { for index, inputValue:= range inputVector { if inputValue > 0.00 { weightVector = weightVector + learningRate } } return weightVector } func evaluate(inputVector float64, weightVector float64) float64 { result:= 0.00 for index, inputValue:= range inputVector { layerValue:= inputValue * weightVector result = result + layerValue } return result } func evaluateError(desired float64, actual float64) float64 { return desired - actual }
Вы можете помочь и перевести немного средств на развитие сайта
Соответственно, нейронная сеть берет на вход два числа и должна на выходе дать другое число - ответ. Теперь о самих нейронных сетях.
Что такое нейронная сеть?
Нейронная сеть - это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1 , Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей - это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.
Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:
Классификация - распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание - возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание - в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?
Нейрон - это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.

Важно помнить , что нейроны оперируют числами в диапазоне или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ - это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?

Синапс это связь между двумя нейронами. У синапсов есть 1 параметр - вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример - смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов - это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить , что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?

В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H - скрытый нейрон, а буквой w - веса. Из формулы видно, что входная информация - это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации - это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия - это диапазон значений.
Линейная функция
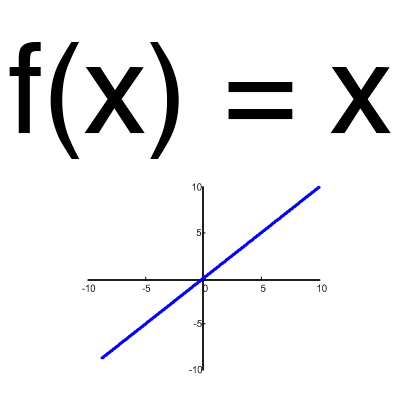
Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид

Это самая распространенная функция активации, ее диапазон значений . Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс

Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет - это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.

Важно
не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка - это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.

Root MSE


Принцип подсчета ошибки во всех случаях одинаков. За каждый сет, мы считаем ошибку, отняв от идеального ответа, полученный. Далее, либо возводим в квадрат, либо вычисляем квадратный тангенс из этой разности, после чего полученное число делим на количество сетов.
Задача
Теперь, чтобы проверить себя, подсчитайте результат, данной нейронной сети, используя сигмоид, и ее ошибку, используя MSE.

Решение
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Большое спасибо за внимание! Надеюсь, что данная статья смогла помочь вам в изучении нейронных сетей. В следующей статье, я расскажу о нейронах смещения и о том, как тренировать нейронную сеть, используя метод обратного распространения и градиентного спуска.
Что такое нейрон смещения?

Перед тем как начать нашу основную тему, мы должны ввести понятие еще одного вида нейронов - нейрон смещения. Нейрон смещения или bias нейрон - это третий вид нейронов, используемый в большинстве нейросетей. Особенность этого типа нейронов заключается в том, что его вход и выход всегда равняются 1 и они никогда не имеют входных синапсов. Нейроны смещения могут, либо присутствовать в нейронной сети по одному на слое, либо полностью отсутствовать, 50/50 быть не может (красным на схеме обозначены веса и нейроны которые размещать нельзя). Соединения у нейронов смещения такие же, как у обычных нейронов - со всеми нейронами следующего уровня, за исключением того, что синапсов между двумя bias нейронами быть не может. Следовательно, их можно размещать на входном слое и всех скрытых слоях, но никак не на выходном слое, так как им попросту не с чем будет формировать связь.
Для чего нужен нейрон смещения?

Нейрон смещения нужен для того, чтобы иметь возможность получать выходной результат, путем сдвига графика функции активации вправо или влево. Если это звучит запутанно, давайте рассмотрим простой пример, где есть один входной нейрон и один выходной нейрон. Тогда можно установить, что выход O2 будет равен входу H1, умноженному на его вес, и пропущенному через функцию активации (формула на фото слева). В нашем конкретном случае, будем использовать сигмоид.
Из школьного курса математики, мы знаем, что если взять функцию y = ax+b и менять у нее значения “а”, то будет изменяться наклон функции (цвета линий на графике слева), а если менять “b”, то мы будем смещать функцию вправо или влево (цвета линий на графике справа). Так вот “а” - это вес H1, а “b” - это вес нейрона смещения B1. Это грубый пример, но примерно так все и работает (если вы посмотрите на функцию активации справа на изображении, то заметите очень сильное сходство между формулами). То есть, когда в ходе обучения, мы регулируем веса скрытых и выходных нейронов, мы меняем наклон функции активации. Однако, регулирование веса нейронов смещения может дать нам возможность сдвинуть функцию активации по оси X и захватить новые участки. Иными словами, если точка, отвечающая за ваше решение, будет находиться, как показано на графике слева, то ваша НС никогда не сможет решить задачу без использования нейронов смещения. Поэтому, вы редко встретите нейронные сети без нейронов смещения.
Также нейроны смещения помогают в том случае, когда все входные нейроны получают на вход 0 и независимо от того какие у них веса, они все передадут на следующий слой 0, но не в случае присутствия нейрона смещения. Наличие или отсутствие нейронов смещения - это гиперпараметр (об этом чуть позже). Одним словом, вы сами должны решить, нужно ли вам использовать нейроны смещения или нет, прогнав НС с нейронами смешения и без них и сравнив результаты.
ВАЖНО знать, что иногда на схемах не обозначают нейроны смещения, а просто учитывают их веса при вычислении входного значения например:
input = H1*w1+H2*w2+b3
b3 = bias*w3
Так как его выход всегда равен 1, то можно просто представить что у нас есть дополнительный синапс с весом и прибавить к сумме этот вес без упоминания самого нейрона.
Как сделать чтобы НС давала правильные ответы?
Ответ прост - нужно ее обучать. Однако, насколько бы прост не был ответ, его реализация в плане простоты, оставляет желать лучшего. Существует несколько методов обучения НС и я выделю 3, на мой взгляд, самых интересных:
- Метод обратного распространения (Backpropagation)
- Метод упругого распространения (Resilient propagation или Rprop)
- Генетический Алгоритм (Genetic Algorithm)
Об Rprop и ГА речь пойдет в других статьях, а сейчас мы с вами посмотрим на основу основ - метод обратного распространения, который использует алгоритм градиентного спуска.
Что такое градиентный спуск?
Это способ нахождения локального минимума или максимума функции с помощью движения вдоль градиента. Если вы поймете суть градиентного спуска, то у вас не должно возникнуть никаких вопросов во время использования метода обратного распространения. Для начала, давайте разберемся, что такое градиент и где он присутствует в нашей НС. Давайте построим график, где по оси х будут значения веса нейрона(w) а по оси у - ошибка соответствующая этому весу(e).

Посмотрев на этот график, мы поймем, что график функция f(w) является зависимостью ошибки от выбранного веса. На этом графике нас интересует глобальный минимум - точка (w2,e2) или, иными словами, то место где график подходит ближе всего к оси х. Эта точка будет означать, что выбрав вес w2 мы получим самую маленькую ошибку - e2 и как следствие, самый лучший результат из всех возможных. Найти же эту точку нам поможет метод градиентного спуска (желтым на графике обозначен градиент). Соответственно у каждого веса в нейросети будет свой график и градиент и у каждого надо найти глобальный минимум.
Так что же такое, этот градиент? Градиент - это вектор который определяет крутизну склона и указывает его направление относительно какой либо из точек на поверхности или графике. Чтобы найти градиент нужно взять производную от графика по данной точке (как это и показано на графике). Двигаясь по направлению этого градиента мы будем плавно скатываться в низину. Теперь представим что ошибка - это лыжник, а график функции - гора. Соответственно, если ошибка равна 100%, то лыжник находиться на самой вершине горы и если ошибка 0% то в низине. Как все лыжники, ошибка стремится как можно быстрее спуститься вниз и уменьшить свое значение. В конечном случае у нас должен получиться следующий результат:

Представьте что лыжника забрасывают, с помощью вертолета, на гору. На сколько высоко или низко зависит от случая (аналогично тому, как в нейронной сети при инициализации веса расставляются в случайном порядке). Допустим ошибка равна 90% и это наша точка отсчета. Теперь лыжнику нужно спуститься вниз, с помощью градиента. На пути вниз, в каждой точке мы будем вычислять градиент, что будет показывать нам направление спуска и при изменении наклона, корректировать его. Если склон будет прямым, то после n-ого количества таких действий мы доберемся до низины. Но в большинстве случаев склон (график функции) будет волнистый и наш лыжник столкнется с очень серьезной проблемой - локальный минимум. Я думаю все знают, что такое локальный и глобальный минимум функции, для освежения памяти вот пример. Попадание в локальный минимум чревато тем, что наш лыжник навсегда останется в этой низине и никогда не скатиться с горы, следовательно мы никогда не сможем получить правильный ответ. Но мы можем избежать этого, снарядив нашего лыжника реактивным ранцем под названием момент (momentum). Вот краткая иллюстрация момента:

Как вы уже наверное догадались, этот ранец придаст лыжнику необходимое ускорение чтобы преодолеть холм, удерживающий нас в локальном минимуме, однако здесь есть одно НО. Представим что мы установили определенное значение параметру момент и без труда смогли преодолеть все локальные минимумы, и добраться до глобального минимума. Так как мы не можем просто отключить реактивный ранец, то мы можем проскочить глобальный минимум, если рядом с ним есть еще низины. В конечном случае это не так важно, так как рано или поздно мы все равно вернемся обратно в глобальный минимум, но стоит помнить, что чем больше момент, тем больше будет размах с которым лыжник будет кататься по низинам. Вместе с моментом в методе обратного распространения также используется такой параметр как скорость обучения (learning rate). Как наверняка многие подумают, чем больше скорость обучения, тем быстрее мы обучим нейросеть. Нет. Скорость обучения, также как и момент, является гиперпараметром - величина которая подбирается путем проб и ошибок. Скорость обучения можно напрямую связать со скоростью лыжника и можно с уверенностью сказать - тише едешь дальше будешь. Однако здесь тоже есть определенные аспекты, так как если мы совсем не дадим лыжнику скорости то он вообще никуда не поедет, а если дадим маленькую скорость то время пути может растянуться на очень и очень большой период времени. Что же тогда произойдет если мы дадим слишком большую скорость?

Как видите, ничего хорошего. Лыжник начнет скатываться по неправильному пути и возможно даже в другом направлении, что как вы понимаете только отдалит нас от нахождения правильного ответа. Поэтому во всех этих параметрах нужно находить золотую середину чтобы избежать не сходимости НС (об этом чуть позже).
Что такое Метод Обратного Распространения (МОР)?
Вот мы и дошли до того момента, когда мы можем обсудить, как же все таки сделать так, чтобы ваша НС могла правильно обучаться и давать верные решения. Очень хорошо МОР визуализирован на этой гифке:

А теперь давайте подробно разберем каждый этап. Если вы помните то в предыдущей статье мы считали выход НС. По другому это называется передача вперед (Forward pass), то есть мы последовательно передаем информацию от входных нейронов к выходным. После чего мы вычисляем ошибку и основываясь на ней делаем обратную передачу, которая заключается в том, чтобы последовательно менять веса нейронной сети, начиная с весов выходного нейрона. Значение весов будут меняться в ту сторону, которая даст нам наилучший результат. В моих вычисления я буду пользоваться методом нахождения дельты, так как это наиболее простой и понятный способ. Также я буду использовать стохастический метод обновления весов (об этом чуть позже).
Теперь давайте продолжим с того места, где мы закончили вычисления в предыдущей статье.
Данные задачи из предыдущей статьи
Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат - 0.33, ошибка - 45%.
Так как мы уже подсчитали результат НС и ее ошибку, то мы можем сразу приступить к МОРу. Как я уже упоминал ранее, алгоритм всегда начинается с выходного нейрона. В таком случае давайте посчитаем для него значение δ (дельта) по формуле 1. Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Таким образом наши вычисления для точки O1 будут выглядеть следующим образом.
Решение
На этом вычисления для нейрона O1 закончены. Запомните, что после подсчета дельты нейрона мы обязаны сразу обновить веса всех исходящих синапсов этого нейрона. Так как в случае с O1 их нет, мы переходим к нейронам скрытого уровня и делаем тоже самое за исключение того, что формула подсчета дельты у нас теперь вторая и ее суть заключается в том, чтобы умножить производную функции активации от входного значения на сумму произведений всех исходящих весов и дельты нейрона с которой этот синапс связан. Но почему формулы разные? Дело в том что вся суть МОР заключается в том чтобы распространить ошибку выходных нейронов на все веса НС. Ошибку можно вычислить только на выходном уровне, как мы это уже сделали, также мы вычислили дельту в которой уже есть эта ошибка. Следственно теперь мы будем вместо ошибки использовать дельту которая будет передаваться от нейрона к нейрону. В таком случае давайте найдем дельту для H1:
Решение
H1output = 0.61
w5 = 1.5
δO1 = 0.148δH1 = ((1 - 0.61) * 0.61) * (1.5 * 0.148) = 0.053
Теперь нам нужно найти градиент для каждого исходящего синапса. Здесь обычно вставляют 3 этажную дробь с кучей производных и прочим математическим адом, но в этом и вся прелесть использования метода подсчета дельт, потому что в конечном счете ваша формула нахождения градиента будет выглядеть вот так:
Здесь точка A это точка в начале синапса, а точка B на конце синапса. Таким образом мы можем подсчитать градиент w5 следующим образом:
Решение
Сейчас у нас есть все необходимые данные чтобы обновить вес w5 и мы сделаем это благодаря функции МОР которая рассчитывает величину на которую нужно изменить тот или иной вес и выглядит она следующим образом:
Настоятельно рекомендую вам не игнорировать вторую часть выражения и использовать момент так как это вам позволит избежать проблем с локальным минимумом.
Здесь мы видим 2 константы о которых мы уже говорили, когда рассматривали алгоритм градиентного спуска: E (эпсилон) - скорость обучения, α (альфа) - момент. Переводя формулу в слова получим: изменение веса синапса равно коэффициенту скорости обучения, умноженному на градиент этого веса, прибавить момент умноженный на предыдущее изменение этого веса (на 1-ой итерации равно 0). В таком случае давайте посчитаем изменение веса w5 и обновим его значение прибавив к нему Δw5.
Решение
Таким образом после применения алгоритма наш вес увеличился на 0.063. Теперь предлагаю сделать вам тоже самое для H2.
Решение
И конечно не забываем про I1 и I2, ведь у них тоже есть синапсы веса которых нам тоже нужно обновить. Однако помним, что нам не нужно находить дельты для входных нейронов так как у них нет входных синапсов.
Решение
Теперь давайте убедимся в том, что мы все сделали правильно и снова посчитаем выход НС только уже с обновленными весами.
Решение
Как мы видим после одной итерации МОР, нам удалось уменьшить ошибку на 0.04 (6%). Теперь нужно повторять это снова и снова, пока ваша ошибка не станет достаточно мала.
Что еще нужно знать о процессе обучения?
Нейросеть можно обучать с учителем и без (supervised, unsupervised learning).
Обучение с учителем - это тип тренировок присущий таким проблемам как регрессия и классификация (им мы и воспользовались в примере приведенном выше). Иными словами здесь вы выступаете в роли учителя а НС в роли ученика. Вы предоставляете входные данные и желаемый результат, то есть ученик посмотрев на входные данные поймет, что нужно стремиться к тому результату который вы ему предоставили.
Обучение без учителя - этот тип обучения встречается не так часто. Здесь нет учителя, поэтому сеть не получает желаемый результат или же их количество очень мало. В основном такой вид тренировок присущ НС у которых задача состоит в группировке данных по определенным параметрам. Допустим вы подаете на вход 10000 статей на хабре и после анализа всех этих статей НС сможет распределить их по категориям основываясь, например, на часто встречающихся словах. Статьи в которых упоминаются языки программирования, к программированию, а где такие слова как Photoshop, к дизайну.
Существует еще такой интересный метод, как обучение с подкреплением (reinforcement learning). Этот метод заслуживает отдельной статьи, но я попытаюсь вкратце описать его суть. Такой способ применим тогда, когда мы можем основываясь на результатах полученных от НС, дать ей оценку. Например мы хотим научить НС играть в PAC-MAN, тогда каждый раз когда НС будет набирать много очков мы будем ее поощрять. Иными словами мы предоставляем НС право найти любой способ достижения цели, до тех пор пока он будет давать хороший результат. Таким способом, сеть начнет понимать чего от нее хотят добиться и пытается найти наилучший способ достижения этой цели без постоянного предоставления данных “учителем”.
Также обучение можно производить тремя методами: стохастический метод (stochastic), пакетный метод (batch) и мини-пакетный метод (mini-batch). Существует очень много статей и исследований на тему того, какой из методов лучше и никто не может прийти к общему ответу. Я же сторонник стохастического метода, однако я не отрицаю тот факт, что каждый метод имеет свои плюсы и минусы.
Вкратце о каждом методе:
Стохастический (его еще иногда называют онлайн) метод работает по следующему принципу - нашел Δw, сразу обнови соответствующий вес.
Пакетный метод же работает по другому. Мы суммируем Δw всех весов на текущей итерации и только потом обновляем все веса используя эту сумму. Один из самых важных плюсов такого подхода - это значительная экономия времени на вычисление, точность же в таком случае может сильно пострадать.
Мини-пакетный метод является золотой серединой и пытается совместить в себе плюсы обоих методов. Здесь принцип таков: мы в свободном порядке распределяем веса по группам и меняем их веса на сумму Δw всех весов в той или иной группе.
Что такое гиперпараметры?
Гиперпараметры - это значения, которые нужно подбирать вручную и зачастую методом проб и ошибок. Среди таких значений можно выделить:
- Момент и скорость обучения
- Количество скрытых слоев
- Количество нейронов в каждом слое
- Наличие или отсутствие нейронов смещения
В других типах НС присутствуют дополнительные гиперпараметры, но о них мы говорить не будем. Подбор верных гиперпараметров очень важен и будет напрямую влиять на сходимость вашей НС. Понять стоит ли использовать нейроны смещения или нет достаточно просто. Количество скрытых слоев и нейронов в них можно вычислить перебором основываясь на одном простом правиле - чем больше нейронов, тем точнее результат и тем экспоненциально больше время, которое вы потратите на ее обучение. Однако стоит помнить, что не стоит делать НС с 1000 нейронов для решения простых задач. А вот с выбором момента и скорости обучения все чуточку сложнее. Эти гиперпараметры будут варьироваться, в зависимости от поставленной задачи и архитектуры НС. Например, для решения XOR скорость обучения может быть в пределах 0.3 - 0.7, но в НС которая анализирует и предсказывает цену акций, скорость обучения выше 0.00001 приводит к плохой сходимости НС. Не стоит сейчас заострять свое внимание на гиперпараметрах и пытаться досконально понять, как же их выбирать. Это придет с опытом, а пока что советую просто экспериментировать и искать примеры решения той или иной задачи в сети.
Что такое сходимость?

Сходимость говорит о том, правильная ли архитектура НС и правильно ли были подобраны гиперпараметры в соответствии с поставленной задачей. Допустим наша программа выводит ошибку НС на каждой итерации в лог. Если с каждой итерацией ошибка будет уменьшаться, то мы на верном пути и наша НС сходится. Если же ошибка будет прыгать вверх - вниз или застынет на определенном уровне, то НС не сходится. В 99% случаев это решается изменением гиперпараметров. Оставшийся 1% будет означать, что у вас ошибка в архитектуре НС. Также бывает, что на сходимость влияет переобучение НС.
Что такое переобучение?
Переобучение, как следует из названия, это состояние нейросети, когда она перенасыщена данными. Это проблема возникает, если слишком долго обучать сеть на одних и тех же данных. Иными словами, сеть начнет не учиться на данных, а запоминать и “зубрить” их. Соответственно, когда вы уже будете подавать на вход этой НС новые данные, то в полученных данных может появиться шум, который будет влиять на точность результата. Например, если мы будем показывать НС разные фотографии яблок (только красные) и говорить что это яблоко. Тогда, когда НС увидит желтое или зеленое яблоко, оно не сможет определить, что это яблоко, так как она запомнила, что все яблоки должны быть красными. И наоборот, когда НС увидит что-то красное и по форме совпадающее с яблоком, например персик, она скажет, что это яблоко. Это и есть шум. На графике шум будет выглядеть следующим образом.

Видно, что график функции сильно колеблется от точки к точке, которые являются выходными данными (результатом) нашей НС. В идеале, этот график должен быть менее волнистый и прямой. Чтобы избежать переобучения, не стоит долго тренировать НС на одних и тех же или очень похожих данных. Также, переобучение может быть вызвано большим количеством параметров, которые вы подаете на вход НС или слишком сложной архитектурой. Таким образом, когда вы замечаете ошибки (шум) в выходных данных после этапа обучения, то вам стоит использовать один из методов регуляризации, но в большинстве случаев это не понадобиться.



