Dzień dobry, nazywam się Natalia Efremova i jestem pracownikiem naukowym w NtechLab. Dziś opowiem o rodzajach sieci neuronowych i ich zastosowaniach.
Na początek powiem kilka słów o naszej firmie. Firma jest nowa, być może wielu z Was jeszcze nie wie czym się zajmujemy. W zeszłym roku zwyciężyliśmy w konkursie MegaFace. To międzynarodowy konkurs rozpoznawania twarzy. W tym samym roku została otwarta nasza firma, czyli istniejemy na rynku około roku, a nawet trochę więcej. Dzięki temu jesteśmy jedną z wiodących firm w dziedzinie rozpoznawania twarzy i przetwarzania obrazu biometrycznego.
Pierwsza część mojego raportu będzie skierowana do osób niezaznajomionych z sieciami neuronowymi. Jestem bezpośrednio zaangażowany w głębokie uczenie się. Pracuję w tej branży od ponad 10 lat. Chociaż pojawiło się to niecałe dziesięć lat temu, istniały pewne podstawy sieci neuronowych podobne do systemu głębokiego uczenia się.
W ciągu ostatnich 10 lat głębokie uczenie się i wizja komputerowa rozwinęły się w niesamowitym tempie. Wszystko, co istotne w tym obszarze zostało zrobione, wydarzyło się w ciągu ostatnich 6 lat.
Opowiem o aspektach praktycznych: gdzie, kiedy, czego użyć w zakresie głębokiego uczenia się do przetwarzania obrazu i wideo, do rozpoznawania obrazu i twarzy, ponieważ pracuję w firmie, która się tym zajmuje. Opowiem Wam trochę o rozpoznawaniu emocji oraz o tym, jakie podejścia stosuje się w grach i robotyce. Opowiem także o niestandardowym zastosowaniu głębokiego uczenia się, które dopiero wyłania się z instytucji naukowych i jest wciąż mało stosowane w praktyce, jak można je zastosować i dlaczego jest trudne w zastosowaniu.
Raport będzie składał się z dwóch części. Ponieważ większość jest zaznajomiona z sieciami neuronowymi, najpierw szybko omówię, jak działają sieci neuronowe, czym są biologiczne sieci neuronowe, dlaczego ważne jest, abyśmy wiedzieli, jak to działa, czym są sztuczne sieci neuronowe i jakie architektury są stosowane w jakich obszarach .
Od razu przepraszam, pominę trochę terminologię angielską, bo nawet nie wiem większości, jak to się nazywa po rosyjsku. Być może ty też.
Zatem pierwsza część raportu będzie poświęcona splotowym sieciom neuronowym. Jak działają splotowe sieci neuronowe (CNN) i rozpoznawanie obrazu, opowiem na przykładzie z rozpoznawania twarzy. Opowiem Wam trochę o rekurencyjnych sieciach neuronowych (RNN) i uczeniu się przez wzmacnianie na przykładzie systemów głębokiego uczenia się.
Jako niestandardowe zastosowanie sieci neuronowych opowiem o tym, jak CNN sprawdza się w medycynie przy rozpoznawaniu obrazów wokselowych, jak sieci neuronowe wykorzystywane są do rozpoznawania biedy w Afryce.
Czym są sieci neuronowe
Prototypem tworzenia sieci neuronowych były, co dziwne, biologiczne sieci neuronowe. Wielu z Was może wiedzieć, jak zaprogramować sieć neuronową, ale myślę, że niektórzy nie wiedzą, skąd się to wzięło. Dwie trzecie wszystkich informacji zmysłowych, które do nas docierają, pochodzi z wizualnych narządów percepcji. Ponad jedną trzecią powierzchni naszego mózgu zajmują dwa najważniejsze obszary wzrokowe – grzbietowa droga wzrokowa i brzuszna droga wzrokowa.Grzbietowa droga wzrokowa rozpoczyna się w pierwotnej strefie widzenia, przy koronie i biegnie w górę, podczas gdy brzuszna droga wzrokowa zaczyna się z tyłu głowy i kończy mniej więcej za uszami. Całe ważne rozpoznawanie wzorców, które nam się przydarza, wszystko, co niesie ze sobą znaczenie, którego jesteśmy świadomi, odbywa się właśnie tam, za uszami.
Dlaczego to jest ważne? Ponieważ często konieczne jest zrozumienie sieci neuronowych. Po pierwsze, wszyscy o tym mówią i już się do tego przyzwyczaiłem, a po drugie, faktem jest, że wszystkie obszary wykorzystywane w sieciach neuronowych do rozpoznawania obrazu docierają do nas właśnie z brzusznej drogi wzrokowej, gdzie każdy strefa odpowiada za swoją ściśle określoną funkcję.
Obraz dociera do nas z siatkówki, przechodzi przez szereg stref wzrokowych i kończy się w strefie skroniowej.
W odległych latach 60. ubiegłego wieku, kiedy dopiero rozpoczynały się badania obszarów wzrokowych mózgu, pierwsze eksperymenty przeprowadzono na zwierzętach, ponieważ nie było fMRI. Mózg badano za pomocą elektrod wszczepionych w różne obszary widzenia.
Pierwszy obszar wizualny został zbadany przez Davida Hubela i Thorstena Wiesela w 1962 roku. Przeprowadzali eksperymenty na kotach. Kotom pokazano różne poruszające się obiekty. Komórki mózgowe zareagowały na bodziec rozpoznany przez zwierzę. Nawet teraz wiele eksperymentów przeprowadza się w ten drakoński sposób. Niemniej jednak jest to najskuteczniejszy sposób, aby dowiedzieć się, co robi każda mała komórka w naszym mózgu.
W ten sam sposób odkryto wiele innych ważnych właściwości obszarów wizualnych, które obecnie wykorzystujemy w głębokim uczeniu się. Jedną z najważniejszych właściwości jest zwiększenie pola recepcyjnego naszych komórek w miarę przemieszczania się z głównych obszarów widzenia do płatów skroniowych, czyli późniejszych obszarów widzenia. Pole recepcyjne to ta część obrazu, którą przetwarza każda komórka naszego mózgu. Każda komórka ma swoje własne pole recepcyjne. Jak zapewne wszyscy wiecie, ta sama właściwość jest zachowywana w sieciach neuronowych.
Ponadto wraz ze wzrostem pól recepcyjnych zwiększają się także złożone bodźce zwykle rozpoznawane przez sieci neuronowe.

Tutaj widzisz przykłady złożoności bodźców, różne dwuwymiarowe kształty rozpoznawane w obszarach V2, V4 i różnych częściach pól skroniowych u makaków. Prowadzonych jest również szereg eksperymentów MRI.

Tutaj możesz zobaczyć, jak przeprowadzane są takie eksperymenty. Jest to 1-nanometrowa część obszarów kory IT małpy podczas rozpoznawania różnych obiektów. Miejsce rozpoznania jest zaznaczone.
Podsumujmy to. Ważną właściwością, którą chcemy przejąć z obszarów wizualnych, jest to, że zwiększa się rozmiar pól recepcyjnych i zwiększa się złożoność rozpoznawanych obiektów.
Wizja komputerowa
Zanim nauczyliśmy się stosować to do widzenia komputerowego, w ogóle nie istniało to. W każdym razie nie działało to tak dobrze, jak działa teraz.Przenosimy wszystkie te właściwości do sieci neuronowej i już działa, jeśli nie dodać małej dygresji na temat zbiorów danych, o czym powiem później.
Ale najpierw trochę o najprostszym perceptronie. Jest on również ukształtowany na obraz i podobieństwo naszego mózgu. Najprostszym elementem przypominającym komórkę mózgową jest neuron. Zawiera elementy wejściowe, które domyślnie są ułożone od lewej do prawej, czasami od dołu do góry. Po lewej stronie znajdują się wejściowe części neuronu, po prawej stronie wyjściowe części neuronu.
Najprostszy perceptron jest w stanie wykonywać tylko najprostsze operacje. Aby wykonać bardziej złożone obliczenia, potrzebujemy konstrukcji z większą liczbą ukrytych warstw.

W przypadku widzenia komputerowego potrzebujemy jeszcze więcej warstw ukrytych. I tylko wtedy system w znaczący sposób rozpozna to, co widzi.
Opowiem więc, co dzieje się podczas rozpoznawania obrazu na przykładzie twarzy.
Dla nas spojrzenie na to zdjęcie i stwierdzenie, że przedstawia ono dokładnie twarz posągu, jest całkiem proste. Jednak przed 2010 rokiem było to niezwykle trudne zadanie dla wizji komputerowej. Ci, którzy już wcześniej mieli do czynienia z tym zagadnieniem, zapewne wiedzą, jak trudno było opisać bez słów przedmiot, który chcemy znaleźć na zdjęciu.
Musieliśmy to zrobić w jakiś geometryczny sposób, opisać obiekt, opisać relacje między obiektem, jak te części mogą się ze sobą powiązać, a następnie znaleźć ten obraz na obiekcie, porównać je i uzyskać to, co słabo rozpoznaliśmy. Zwykle było to trochę lepsze niż rzucenie monetą. Nieco lepszy niż poziom szansy.
To nie tak teraz działa. Nasz obraz dzielimy albo na piksele, albo na określone obszary: 2x2, 3x3, 5x5, 11x11 pikseli - tak jak jest to wygodne dla twórców systemu, w którym służą one jako warstwa wejściowa dla sieci neuronowej.
Sygnały z tych warstw wejściowych są przesyłane z warstwy do warstwy za pomocą synaps, przy czym każda warstwa ma swoje własne, specyficzne współczynniki. Przechodzimy więc z warstwy na warstwę, z warstwy na warstwę, aż rozpoznamy twarz.
Konwencjonalnie wszystkie te części można podzielić na trzy klasy, oznaczymy je X, W i Y, gdzie X jest naszym obrazem wejściowym, Y jest zbiorem etykiet i musimy uzyskać nasze wagi. Jak obliczyć W?
Biorąc pod uwagę nasze X i Y, wydaje się to proste. Jednak to, co jest oznaczone gwiazdką, jest bardzo złożoną operacją nieliniową, która niestety nie ma odwrotności. Nawet przy danych 2 składnikach równania bardzo trudno jest je obliczyć. Trzeba więc stopniowo, metodą prób i błędów, dobierając wagę W, upewnić się, że błąd maleje jak najbardziej, najlepiej tak, aby był równy zeru.

Proces ten zachodzi iteracyjnie, stale redukujemy, aż znajdziemy taką wartość wagi W, która będzie nam dostatecznie odpowiadać.
Nawiasem mówiąc, ani jedna sieć neuronowa, z którą pracowałem, nie osiągnęła błędu równego zero, ale działała całkiem nieźle.

To pierwsza sieć, która w 2012 roku zwyciężyła w międzynarodowym konkursie ImageNet. Jest to tak zwany AlexNet. Jest to sieć, która jako pierwsza oświadczyła, że istnieją splotowe sieci neuronowe i od tego czasu splotowe sieci neuronowe nie zrezygnowały ze swoich pozycji we wszystkich międzynarodowych konkursach.
Pomimo tego, że sieć ta jest dość mała (ma tylko 7 warstw ukrytych), zawiera 650 tysięcy neuronów z 60 milionami parametrów. Aby iteracyjnie nauczyć się znajdować niezbędne wagi, potrzebujemy wielu przykładów.
Sieć neuronowa uczy się na przykładzie zdjęcia i etykiety. Tak jak uczy się nas w dzieciństwie „to jest kot, a to jest pies”, sieci neuronowe są trenowane na dużej liczbie obrazów. Ale faktem jest, że do 2010 roku nie było wystarczająco dużego zbioru danych, który mógłby nauczyć tak wielu parametrów rozpoznawania obrazów.
Największe bazy danych, jakie istniały wcześniej, to PASCAL VOC, który zawierał tylko 20 kategorii obiektów, oraz Caltech 101, który został opracowany w California Institute of Technology. Ostatni miał 101 kategorii, a to dużo. Ci, którym nie udało się znaleźć swoich obiektów w żadnej z tych baz, musieli ponieść koszty swoich baz danych, co, powiem, jest strasznie bolesne.
Natomiast w 2010 roku pojawiła się baza ImageNet, która zawierała 15 milionów obrazów, podzielonych na 22 tysiące kategorii. To rozwiązało nasz problem uczenia sieci neuronowych. Teraz każdy, kto posiada adres akademicki, może z łatwością wejść na stronę bazy, poprosić o dostęp i otrzymać tę bazę do szkolenia swoich sieci neuronowych. Moim zdaniem reagują dość szybko już następnego dnia.
W porównaniu z poprzednimi zbiorami danych jest to bardzo duża baza danych.

Przykład pokazuje, jak nieistotne było wszystko, co było wcześniej. Równolegle z bazą ImageNet pojawił się konkurs ImageNet, międzynarodowe wyzwanie, w którym mogą wziąć udział wszystkie zespoły chcące rywalizować.
W tym roku zwycięska sieć powstała w Chinach i liczyła 269 warstw. Nie wiem, ile jest tych parametrów, podejrzewam, że jest ich też sporo.
Architektura głębokiej sieci neuronowej
Umownie można go podzielić na 2 części: studiujących i niestudiujących.
Kolor czarny wskazuje te części, które się nie uczą; wszystkie pozostałe warstwy są zdolne do uczenia się. Istnieje wiele definicji tego, co znajduje się wewnątrz każdej warstwy splotowej. Jednym z przyjętych zapisów jest to, że jedna warstwa z trzema składnikami jest podzielona na etap splotu, etap detektora i etap łączenia.
Nie będę wdawał się w szczegóły; będzie znacznie więcej raportów szczegółowo omawiających, jak to działa. Opowiem Ci na przykładzie.
Ponieważ organizatorzy poprosili mnie, abym nie wymieniała wielu formuł, całkowicie je wyrzuciłam.

Obraz wejściowy wpada więc w sieć warstw, które można nazwać filtrami o różnej wielkości i różnym stopniu złożoności rozpoznawanych przez nie elementów. Filtry te tworzą własny indeks lub zestaw cech, które następnie trafiają do klasyfikatora. Zwykle jest to SVM lub MLP – perceptron wielowarstwowy, w zależności od tego, co jest dla Ciebie wygodne.
Podobnie jak biologiczna sieć neuronowa, rozpoznawane są obiekty o różnym stopniu złożoności. Wraz ze wzrostem liczby warstw wszystko straciło kontakt z korą, ponieważ liczba stref w sieci neuronowej jest ograniczona. 269, czyli wiele, wiele stref abstrakcji, więc zostaje zachowany jedynie wzrost złożoności, liczby elementów i pól recepcyjnych.

Jeśli spojrzymy na przykład rozpoznawania twarzy, to nasze pole recepcyjne pierwszej warstwy będzie małe, potem trochę większe, większe i tak dalej, aż w końcu będziemy mogli rozpoznać całą twarz.

Z punktu widzenia tego, co znajduje się w naszych filtrach, najpierw będą to pochyłe patyki plus trochę koloru, potem fragmenty twarzy, a na końcu przez każdą komórkę warstwy zostaną rozpoznane całe twarze.
Są ludzie, którzy twierdzą, że człowiek zawsze rozpoznaje lepiej niż sieć. Czy tak jest?
W 2014 roku naukowcy postanowili sprawdzić, jak dobrze rozpoznajemy w porównaniu z sieciami neuronowymi. Wzięli 2 najlepsze obecnie sieci – AlexNet oraz sieć Matthew Zillera i Fergusa i porównali je z reakcją różnych obszarów mózgu makaka, którego uczono także rozpoznawać niektóre obiekty. Przedmioty pochodziły ze świata zwierząt, aby małpa nie pomyliła się, i przeprowadzono eksperymenty, aby zobaczyć, kto będzie lepiej rozpoznawał.
Ponieważ uzyskanie jednoznacznej odpowiedzi od małpy nie jest możliwe, wszczepiono jej elektrody i bezpośrednio zmierzono reakcję każdego neuronu.
Okazało się, że w normalnych warunkach komórki mózgowe reagowały tak samo, jak najnowocześniejszy wówczas model, czyli sieć Matthew Zillera.
Jednak wraz ze wzrostem szybkości wyświetlania obiektów oraz wzrostem ilości szumu i obiektów na obrazie, szybkość i jakość rozpoznawania naszego mózgu i mózgu naczelnych znacznie spada. Nawet najprostsza splotowa sieć neuronowa może lepiej rozpoznawać obiekty. Oznacza to, że oficjalnie sieci neuronowe działają lepiej niż nasze mózgi.
Klasyczne problemy splotowych sieci neuronowych
W rzeczywistości nie jest ich wiele; należą do trzech klas. Wśród nich znajdują się takie zadania, jak identyfikacja obiektów, segmentacja semantyczna, rozpoznawanie twarzy, rozpoznawanie części ciała ludzkiego, wykrywanie krawędzi semantycznych, wyróżnianie obiektów uwagi na obrazie i podkreślanie normalnych powierzchni. Można je z grubsza podzielić na 3 poziomy: od zadań najniższego poziomu do zadań najwyższego poziomu.
Używając tego obrazu jako przykładu, przyjrzyjmy się działaniu każdego zadania.
- Definiowanie granic- To zadanie najniższego szczebla, do którego klasycznie wykorzystuje się już splotowe sieci neuronowe.
- Wyznaczanie wektora do normalnej pozwala nam zrekonstruować obraz trójwymiarowy z obrazu dwuwymiarowego.
- Istotność, identyfikacja obiektów uwagi- na to właśnie zwróciłby uwagę człowiek patrząc na to zdjęcie.
- Semantyczna segmentacja pozwala dzielić obiekty na klasy według ich struktury, nie wiedząc nic o tych obiektach, czyli jeszcze zanim zostaną rozpoznane.
- Podświetlanie granic semantycznych- jest to wybór granic podzielonych na klasy.
- Podkreślanie części ludzkiego ciała.
- A zadaniem najwyższego poziomu jest rozpoznawanie samych obiektów, które teraz rozważymy na przykładzie rozpoznawania twarzy.
Rozpoznawanie twarzy
Pierwszą rzeczą, którą robimy, jest uruchomienie detektora twarzy nad obrazem w celu znalezienia twarzy. Następnie normalizujemy, wyśrodkowujemy twarz i uruchamiamy ją w celu przetworzenia w sieci neuronowej, po czym uzyskujemy zestaw lub wektor cech, które są unikalne opisuje cechy tej twarzy.
Następnie możemy porównać ten wektor cech ze wszystkimi wektorami cech, które są przechowywane w naszej bazie danych i uzyskać odniesienie do konkretnej osoby, do jej nazwiska, do jej profilu – wszystko, co możemy przechowywać w bazie danych.
Dokładnie tak działa nasz produkt FindFace - jest to bezpłatna usługa, która pomaga wyszukiwać profile osób w bazie VKontakte.
Dodatkowo posiadamy API dla firm chcących wypróbować nasze produkty. Świadczymy usługi w zakresie wykrywania twarzy, weryfikacji i identyfikacji użytkowników.
Opracowaliśmy obecnie 2 scenariusze. Pierwsza to identyfikacja, czyli wyszukiwanie osoby w bazie danych. Drugi to weryfikacja, czyli porównanie dwóch obrazów z pewnym prawdopodobieństwem, że jest to ta sama osoba. Ponadto obecnie pracujemy nad rozpoznawaniem emocji, rozpoznawaniem obrazu na wideo oraz wykrywaniem żywości – czyli rozumieniem, czy osoba przed aparatem lub zdjęciem żyje.
Trochę statystyk. Przy identyfikacji, przeszukując 10 tysięcy zdjęć, mamy dokładność na poziomie około 95%, w zależności od jakości bazy, i 99% dokładność weryfikacji. A poza tym algorytm ten jest bardzo odporny na zmiany – nie musimy patrzeć w kamerę, mogą nam przeszkadzać jakieś przedmioty: okulary, okulary przeciwsłoneczne, broda, maska lekarska. W niektórych przypadkach możemy nawet pokonać niesamowite wyzwania związane z widzeniem komputerowym, takie jak okulary i maska.
Bardzo szybkie wyszukiwanie, przetworzenie 1 miliarda zdjęć zajmuje 0,5 sekundy. Opracowaliśmy unikalny indeks szybkiego wyszukiwania. Możemy także pracować z obrazami niskiej jakości uzyskanymi z kamer CCTV. Wszystko to możemy przetwarzać w czasie rzeczywistym. Możesz przesyłać zdjęcia za pośrednictwem interfejsu internetowego, systemu Android, iOS i przeszukiwać 100 milionów użytkowników i ich 250 milionów zdjęć.
Jak już mówiłem, zajęliśmy pierwsze miejsce w konkursie MegaFace – analogii do ImageNet, ale do rozpoznawania twarzy. Działa już od kilku lat, w zeszłym roku byliśmy najlepsi spośród 100 drużyn z całego świata, w tym Google.
Rekurencyjne sieci neuronowe
Rekurencyjne sieci neuronowe wykorzystujemy wtedy, gdy nie wystarczy nam rozpoznanie samego obrazu. W przypadkach, gdy ważne jest dla nas zachowanie spójności, potrzebny jest porządek tego, co się dzieje, korzystamy ze zwykłych rekurencyjnych sieci neuronowych.Służy do rozpoznawania języka naturalnego, przetwarzania wideo, a nawet do rozpoznawania obrazu.
O rozpoznawaniu języka naturalnego nie będę już mówił – po moim raporcie pojawią się jeszcze dwa, które będą miały na celu rozpoznawanie języka naturalnego. Dlatego o działaniu sieci rekurencyjnych opowiem na przykładzie rozpoznawania emocji.
Co to są rekurencyjne sieci neuronowe? To mniej więcej to samo, co w przypadku zwykłych sieci neuronowych, ale ze sprzężeniem zwrotnym. Potrzebujemy informacji zwrotnej, aby przekazać poprzedni stan systemu na wejście sieci neuronowej lub do niektórych jej warstw.
Powiedzmy, że przetwarzamy emocje. Nawet w uśmiechu – jednej z najprostszych emocji – jest kilka momentów: od neutralnego wyrazu twarzy do momentu, w którym mamy pełny uśmiech. Następują po sobie sekwencyjnie. Aby to dobrze zrozumieć, musimy umieć obserwować, jak to się dzieje, aby przenieść to, co było na poprzedniej klatce, do kolejnego kroku systemu.

W 2005 roku podczas zawodów Emotion Recognition in the Wild zespół z Montrealu zaprezentował system powtarzalnego rozpoznawania emocji, który wyglądał na bardzo prosty. Miał tylko kilka warstw splotowych i działał wyłącznie z wideo. W tym roku dodali także rozpoznawanie dźwięku i zagregowali dane klatka po klatce uzyskane ze splotowych sieci neuronowych, dane sygnału audio z działaniem rekurencyjnej sieci neuronowej (ze zwrotem stanu) i zajęli pierwsze miejsce w konkursie.
Uczenie się przez wzmacnianie
Kolejnym rodzajem sieci neuronowych, który jest ostatnio bardzo często stosowany, ale nie zyskał tak dużego rozgłosu jak poprzednie 2 typy, jest uczenie się przez głębokie wzmacnianie.Faktem jest, że w dwóch poprzednich przypadkach korzystamy z baz danych. Mamy albo dane z twarzy, albo dane ze zdjęć, albo dane z emocjami z filmów. Jeśli tego nie mamy, jeśli nie możemy tego sfilmować, jak możemy nauczyć robota podnosić przedmioty? Robimy to automatycznie – nie wiemy jak to działa. Inny przykład: kompilowanie dużych baz danych w grach komputerowych jest trudne i nie jest konieczne, można to zrobić znacznie łatwiej;
O sukcesie głębokiego uczenia przez wzmacnianie w Atari i Go zapewne słyszał każdy.
Kto słyszał o Atari? No cóż, ktoś usłyszał, ok. Chyba każdy słyszał o AlphaGo, więc nawet nie będę Wam opowiadał, co dokładnie się tam dzieje.

Co się dzieje na Atari? Architekturę tej sieci neuronowej pokazano po lewej stronie. Uczy się bawiąc się sobą, aby uzyskać maksymalną nagrodę. Maksymalna nagroda to najszybszy możliwy wynik gry z najwyższym możliwym wynikiem.
W prawym górnym rogu znajduje się ostatnia warstwa sieci neuronowej, która przedstawia całą liczbę stanów systemu, który grał przeciwko sobie zaledwie przez dwie godziny. Pożądane wyniki gry z maksymalną nagrodą są zaznaczone na czerwono, a niepożądane na niebiesko. Sieć buduje określone pole i przechodzi przez wytrenowane warstwy do stanu, jaki chce osiągnąć.
W robotyce sytuacja jest nieco inna. Dlaczego? Tutaj mamy kilka trudności. Po pierwsze, nie mamy zbyt wielu baz danych. Po drugie, musimy skoordynować jednocześnie trzy systemy: percepcję robota, jego działania za pomocą manipulatorów i jego pamięć – co zostało zrobione w poprzednim kroku i jak to zostało zrobione. Ogólnie rzecz biorąc, to wszystko jest bardzo trudne.
Faktem jest, że ani jedna sieć neuronowa, nawet obecnie deep learning, nie jest w stanie wystarczająco skutecznie poradzić sobie z tym zadaniem, więc deep learning to tylko wycinek tego, co muszą zrobić roboty. Na przykład Siergiej Levin niedawno udostępnił system, który uczy robota chwytania przedmiotów.

Oto eksperymenty, które przeprowadził na swoich 14 robotycznych ramionach.
Co tu się dzieje? W tych misach, które widzisz przed sobą, znajdują się różne przedmioty: długopisy, gumki, mniejsze i większe kubki, szmaty, różne tekstury, różna twardość. Nie jest jasne, jak nauczyć robota chwytania ich. Przez wiele godzin, a nawet tygodni, roboty szkolono w zakresie chwytania tych obiektów i tworzono na ten temat bazy danych.
Bazy danych to rodzaj reakcji środowiska, którą musimy gromadzić, aby móc wytrenować robota, aby coś zrobił w przyszłości. W przyszłości roboty będą uczyć się na podstawie tego zestawu stanów systemu.
Niestandardowe zastosowania sieci neuronowych
Niestety to już koniec, nie mam dużo czasu. Opowiem o tych niestandardowych rozwiązaniach, które obecnie istnieją i które według wielu prognoz znajdą zastosowanie w przyszłości.Cóż, naukowcy ze Stanford wpadli ostatnio na bardzo nietypowe zastosowanie sieci neuronowej CNN do przewidywania ubóstwa. Co oni zrobili?
Koncepcja jest w rzeczywistości bardzo prosta. Faktem jest, że w Afryce poziom ubóstwa przekracza wszelkie wyobrażalne i niepojęte granice. Nie mają nawet możliwości gromadzenia danych społeczno-demograficznych. Dlatego od 2005 roku nie mamy żadnych danych na temat tego, co się tam dzieje.
Naukowcy zebrali mapy dzienne i nocne z satelitów i przez pewien czas przesyłali je do sieci neuronowej.
Sieć neuronowa została wstępnie skonfigurowana na ImageNet, czyli pierwsze warstwy filtrów zostały skonfigurowane tak, aby mogła rozpoznawać bardzo proste rzeczy, np. dachy domów, aby wyszukiwać osady na mapach dziennych w porównaniu z mapami nocnymi oświetlenia tego samego obszaru powierzchni, aby określić, ile pieniędzy ma ludność, aby przynajmniej oświetlić swoje domy w nocy.

Tutaj widzisz wyniki prognozy zbudowanej przez sieć neuronową. Prognozę sporządzono w różnych rozdzielczościach. I widzicie – w ostatniej klatce – prawdziwe dane zebrane przez rząd Ugandy w 2005 roku.
Widać, że sieć neuronowa sporządziła dość dokładną prognozę, nawet z niewielką zmianą od 2005 roku.
Oczywiście, że były skutki uboczne. Naukowcy zajmujący się głębokim uczeniem są zawsze zaskoczeni odkryciem różnych skutków ubocznych. Na przykład to, że sieć nauczyła się rozpoznawać wodę, lasy, duże budowy, drogi – a to wszystko bez nauczycieli, bez gotowych baz danych. Ogólnie całkowicie niezależnie. Były pewne warstwy, które reagowały na przykład na drogi.
Ostatnim zastosowaniem, o którym chciałbym wspomnieć, jest segmentacja semantyczna obrazów 3D w medycynie. Ogólnie rzecz biorąc, obrazowanie medyczne jest złożoną dziedziną, w której bardzo trudno jest pracować.
Jest tego kilka powodów.
- Mamy bardzo mało baz danych. Znalezienie zdjęcia mózgu, w dodatku uszkodzonego, nie jest takie proste, a poza tym nie da się go skądkolwiek zabrać.
- Nawet jeśli mamy taki obraz, musimy wziąć medyka i zmusić go do ręcznego umieszczania wszystkich wielowarstwowych obrazów, co jest bardzo czasochłonne i wyjątkowo nieefektywne. Nie wszyscy lekarze mają na to środki.
- Wymagana jest bardzo duża precyzja. System medyczny nie może popełniać błędów. Przy rozpoznawaniu np. kotów nie rozpoznano - nic wielkiego. A jeśli nie rozpoznaliśmy guza, to nie jest to już zbyt dobre. Wymagania dotyczące niezawodności systemu są tutaj szczególnie rygorystyczne.
- Obrazy składają się z elementów trójwymiarowych – wokseli, a nie pikseli, co stanowi dodatkową złożoność dla twórców systemów.
Gdzie jest stosowany: identyfikacja uszkodzeń po uderzeniu, poszukiwanie guza w mózgu, w kardiologii w celu określenia pracy serca.

Oto przykład określenia objętości łożyska.
Automatycznie działa dobrze, ale nie na tyle dobrze, aby można go było wypuścić do produkcji, więc dopiero się zaczyna. Istnieje kilka startupów, które zajmują się tworzeniem takich medycznych systemów wizyjnych. Ogólnie rzecz biorąc, w najbliższej przyszłości będzie wiele startupów zajmujących się głębokim uczeniem. Mówią, że w ciągu ostatnich sześciu miesięcy inwestorzy venture capital przeznaczyli więcej budżetu na startupy zajmujące się głębokim uczeniem się niż w ciągu ostatnich 5 lat.
Obszar ten aktywnie się rozwija, istnieje wiele ciekawych kierunków. Żyjemy w ciekawych czasach. Jeśli zajmujesz się głębokim uczeniem, to prawdopodobnie nadszedł czas, abyś otworzył własny startup.
Cóż, prawdopodobnie zakończę to tutaj. Dziękuję bardzo.
Prawidłowe sformułowanie pytania powinno brzmieć: jak trenować własną sieć neuronową? Nie musisz sam pisać sieci; musisz skorzystać z jednej z gotowych implementacji, których jest wiele, linki udostępnili poprzedni autorzy. Ale sama implementacja przypomina komputer, na który nie zostały pobrane żadne programy. Aby sieć rozwiązała Twój problem, trzeba ją nauczyć.
I tu pojawia się najważniejsza rzecz, której potrzebujesz do tego: DANE. Istnieje wiele przykładów problemów, które zostaną wprowadzone na wejście sieci neuronowej i poprawnych odpowiedzi na te problemy. Sieć neuronowa będzie się z tego uczyć, aby samodzielnie udzielać tych poprawnych odpowiedzi.
I tutaj pojawia się szereg szczegółów i niuansów, które musisz poznać i zrozumieć, aby wszystko to miało szansę dać akceptowalny wynik. Nie sposób omówić ich tutaj wszystkich, dlatego wymienię tylko kilka punktów. Po pierwsze, ilość danych. To bardzo ważny punkt. Duże firmy, których działalność związana jest z uczeniem maszynowym, posiadają zazwyczaj specjalne działy i kadrę zajmującą się wyłącznie gromadzeniem i przetwarzaniem danych na potrzeby uczenia sieci neuronowych. Często trzeba kupić dane, a cała ta czynność skutkuje znaczną pozycją wydatków. Po drugie, prezentacja danych. Jeśli każdy obiekt w Twoim problemie jest reprezentowany przez stosunkowo niewielką liczbę parametrów numerycznych, to jest szansa, że uda się je przekazać bezpośrednio do sieci neuronowej w tak surowej postaci i uzyskać akceptowalny wynik wyjściowy. Ale jeśli obiekty są złożone (obrazy, dźwięk, obiekty o zmiennych wymiarach), najprawdopodobniej będziesz musiał poświęcić czas i wysiłek na wydobycie z nich cech znaczących dla rozwiązywanego problemu. Samo to może zająć dużo czasu i mieć znacznie większy wpływ na wynik końcowy niż nawet rodzaj i architektura sieci neuronowej wybranej do zastosowania.
Często zdarza się, że rzeczywiste dane okazują się zbyt surowe i nienadające się do wykorzystania bez wstępnego przetworzenia: zawierają pominięcia, szumy, niespójności i błędy.
Dane należy także zbierać nie byle jak, ale kompetentnie i przemyślanie. W przeciwnym razie wyszkolona sieć może zachowywać się dziwnie, a nawet rozwiązać zupełnie inny problem, niż zamierzył autor.
Trzeba także wyobrazić sobie, jak odpowiednio zorganizować proces uczenia się, aby sieć nie uległa przetrenowaniu. Złożoność sieci należy wybrać na podstawie rozmiaru danych i ich ilości. Część danych należy pozostawić do testów i nie wykorzystywać podczas szkoleń, aby ocenić rzeczywistą jakość pracy. Czasami różnym obiektom w zbiorze szkoleniowym należy przypisać różne wagi. Czasami warto zmieniać te wagi w procesie uczenia się. Czasami przydatne jest rozpoczęcie uczenia części danych i dodawanie pozostałych danych w miarę postępu uczenia. Ogólnie można to porównać do gotowania: każda gospodyni domowa ma swoje własne techniki przygotowywania nawet tych samych potraw.
Artykuł ten zawiera materiały – głównie w języku rosyjskim – do podstawowego badania sztucznych sieci neuronowych.
Sztuczna sieć neuronowa, w skrócie SSN, to model matematyczny, a także jego oprogramowanie lub sprzęt, zbudowany w oparciu o zasadę organizacji i funkcjonowania biologicznych sieci neuronowych – sieci komórek nerwowych żywego organizmu. Nauka o sieciach neuronowych istnieje już od dawna, jednak właśnie w związku z najnowszymi osiągnięciami postępu naukowo-technicznego dziedzina ta zaczyna zyskiwać na popularności.
Książki
Selekcję zacznijmy od klasycznego sposobu nauki – poprzez książki. Wybraliśmy książki w języku rosyjskim z dużą liczbą przykładów:
- F. Wasserman, Technologia neurokomputerowa: Teoria i praktyka. 1992
Książka w ogólnodostępnej formie przedstawia podstawy budowy neurokomputerów. Opisano strukturę sieci neuronowych oraz różne algorytmy ich konfiguracji. Osobne rozdziały poświęcono implementacji sieci neuronowych. - S. Khaikin, Sieci neuronowe: Kompletny kurs. 2006
Omówiono tutaj główne paradygmaty sztucznych sieci neuronowych. Prezentowany materiał zawiera ścisłe uzasadnienie matematyczne wszystkich paradygmatów sieci neuronowych, jest ilustrowany przykładami, opisami eksperymentów komputerowych, zawiera wiele problemów praktycznych, a także obszerną bibliografię.
D. Forsythe, Wizja komputerowa. Nowoczesne podejście. 2004
Wizja komputerowa jest jedną z najpopularniejszych dziedzin na tym etapie rozwoju światowych cyfrowych technologii komputerowych. Jest wymagany w produkcji, sterowaniu robotami, automatyzacji procesów, zastosowaniach medycznych i wojskowych, nadzorze satelitarnym i zastosowaniach komputerów osobistych, takich jak wyszukiwanie obrazów cyfrowych.
Wideo
Nie ma nic bardziej przystępnego i zrozumiałego niż nauka wizualna za pomocą wideo:
- Aby ogólnie zrozumieć, czym jest uczenie maszynowe, spójrz tutaj te dwa wykłady od Yandex ShaD.
- Wstęp w podstawowe zasady projektowania sieci neuronowych – idealne do kontynuowania nauki o sieciach neuronowych.
- Kurs wykładowy na temat „Wizja komputerowa” na Moskiewskim Uniwersytecie Państwowym Maszyn Komputerowych. Wizja komputerowa to teoria i technologia tworzenia sztucznych systemów, które wykrywają i klasyfikują obiekty na obrazach i filmach. Wykłady te można uznać za wprowadzenie do tej ciekawej i złożonej nauki.
Zasoby edukacyjne i przydatne linki
- Portal sztucznej inteligencji.
- Laboratorium „Jestem inteligencją”.
- Sieci neuronowe w Matlabie.
- Sieci neuronowe w Pythonie (angielski):
- Klasyfikacja tekstu za pomocą ;
- Prosty .
- Sieć neuronowa włączona.
Seria naszych publikacji na ten temat
Już wcześniej opublikowaliśmy kurs #neuralnetwork@tproger w sieciach neuronowych. Dla Twojej wygody publikacje na tej liście ułożone są w kolejności studiowania.
Wiele terminów występujących w sieciach neuronowych ma związek z biologią, więc zacznijmy od początku:
Mózg jest złożoną rzeczą, ale można go podzielić na kilka głównych części i operacji:

Czynnikiem sprawczym może być wewnętrzny(na przykład obraz lub pomysł):

Przyjrzyjmy się teraz elementom podstawowym i uproszczonym Części mózg:

Mózg ogólnie przypomina sieć kablową.
Neuron- podstawowa jednostka obliczeniowa w mózgu, odbiera i przetwarza sygnały chemiczne z innych neuronów oraz, w zależności od wielu czynników, albo nie robi nic, albo generuje impuls elektryczny, czyli Potencjał Działania, który następnie wysyła sygnały przez synapsy do sąsiadujących neuronów te powiązany neurony:

Sny, wspomnienia, ruchy samoregulujące, odruchy i w ogóle wszystko, co myślisz lub robisz - wszystko dzieje się dzięki temu procesowi: miliony, a nawet miliardy neuronów pracują na różnych poziomach i tworzą połączenia, które tworzą różne równoległe podsystemy i reprezentują neuron biologiczny internet.
Oczywiście są to wszystko uproszczenia i uogólnienia, ale dzięki nim możemy opisać coś prostego
sieć neuronowa:

I opisz to formalnie za pomocą wykresu:

Tu potrzebne jest pewne wyjaśnienie. Okręgi to neurony, a linie to połączenia między nimi,
i żeby w tym momencie było wszystko proste, relacje reprezentują bezpośredni przepływ informacji od lewej do prawej. Pierwszy neuron jest obecnie aktywny i podświetlony na szaro. Przydzieliliśmy mu także numer (1 jeśli działa, 0 jeśli nie). Pokazują się liczby pomiędzy neuronami waga komunikacja.
Powyższe wykresy pokazują moment sieci; aby uzyskać dokładniejsze przedstawienie, należy podzielić go na okresy:

Aby stworzyć własną sieć neuronową, musisz zrozumieć, jak ciężary wpływają na neurony i jak neurony się uczą. Jako przykład weźmy królika (królika testowego) i umieśćmy go w warunkach klasycznego eksperymentu.

Kiedy kierowany jest na nie bezpieczny strumień powietrza, króliki, podobnie jak ludzie, mrugają:

Ten model zachowania można przedstawić na wykresach:

Podobnie jak na poprzednim diagramie, wykresy te pokazują tylko moment, w którym królik czuje oddech, a my tym samym kodować wiff jako wartość logiczna. Ponadto obliczamy, czy drugi neuron odpala, na podstawie wartości wagi. Jeśli jest równe 1, neuron czuciowy odpala, mrugamy; jeśli waga jest mniejsza niż 1, nie mrugamy: drugi neuron limit- 1.
Wprowadźmy jeszcze jeden element – bezpieczny sygnał dźwiękowy:

Możemy modelować zainteresowanie królika w następujący sposób:

Główna różnica polega na tym, że teraz waga jest równa zero, więc nie dostaliśmy mrugającego królika, cóż, przynajmniej jeszcze nie. Teraz nauczmy królika mrugać na komendę, mieszając
Bodźce (sygnał dźwiękowy i dmuchanie):

Ważne jest, aby zdarzenia te miały miejsce w różnym czasie era, na wykresach będzie to wyglądać następująco:

Sam dźwięk nic nie robi, ale przepływ powietrza nadal powoduje, że królik mruga, co pokazujemy poprzez wagi pomnożone przez bodźce (na czerwono).
Edukacja złożone zachowanie można w uproszczeniu wyrazić jako stopniową zmianę masy pomiędzy połączonymi neuronami w czasie.
Aby wytresować królika, powtarzamy kroki:

Dla pierwszych trzech prób schematy będą wyglądać następująco:

Należy pamiętać, że waga bodźca dźwiękowego zwiększa się po każdym powtórzeniu (zaznaczona na czerwono), wartość ta jest obecnie dowolna - wybraliśmy 0,30, ale liczba może być dowolna, nawet ujemna. Po trzecim powtórzeniu nie zauważysz zmiany w zachowaniu królika, ale po czwartym powtórzeniu stanie się coś niesamowitego – zachowanie się zmieni.

Usunęliśmy ekspozycję na powietrze, ale królik nadal mruga, gdy słyszy sygnał dźwiękowy! Nasz ostatni diagram może wyjaśnić to zachowanie:

Nauczyliśmy królika reagować na dźwięk mruganiem.

W prawdziwym eksperymencie tego rodzaju osiągnięcie wyniku może zająć ponad 60 powtórzeń.
Teraz opuścimy biologiczny świat mózgu i królików i spróbujemy wszystko zaadaptować
nauczył się tworzyć sztuczną sieć neuronową. Najpierw spróbujmy wykonać proste zadanie.
Załóżmy, że mamy maszynę z czterema przyciskami, która wydaje jedzenie po naciśnięciu właściwego
przyciski (no cóż, lub energia, jeśli jesteś robotem). Zadanie polega na tym, aby dowiedzieć się, który przycisk daje nagrodę:

Możemy przedstawić (schematycznie) działanie przycisku po kliknięciu w ten sposób:

Najlepiej rozwiązać ten problem całkowicie, więc przyjrzyjmy się wszystkim możliwym wynikom, łącznie z tym właściwym:

Kliknij trzeci przycisk, aby otrzymać obiad.
Aby odtworzyć sieć neuronową w kodzie, musimy najpierw stworzyć model lub wykres, z którym można porównać sieć. Oto jeden wykres odpowiedni do tego zadania; ponadto dobrze pokazuje jego biologiczny odpowiednik:

Ta sieć neuronowa po prostu odbiera przychodzące informacje – w tym przypadku byłoby to wyczucie, który przycisk został naciśnięty. Następnie sieć zastępuje przychodzące informacje wagami i wyciąga wnioski na podstawie dodania warstwy. Brzmi to trochę zagmatwanie, ale zobaczmy, jak przycisk jest reprezentowany w naszym modelu:

Zauważ, że wszystkie wagi wynoszą 0, więc sieć neuronowa jest jak dziecko, całkowicie pusta, ale całkowicie połączona.
W ten sposób dopasowujemy zdarzenie zewnętrzne do warstwy wejściowej sieci neuronowej i obliczamy wartość na jej wyjściu. Może to pokrywać się z rzeczywistością lub nie, ale na razie zignorujemy to i zaczniemy opisywać problem w sposób zrozumiały dla komputera. Zacznijmy od wpisania wag (użyjemy JavaScript):
Różne wejścia = ; var wagi = ; // Dla wygody wektory te można wywołać
Następnym krokiem jest utworzenie funkcji, która pobiera wartości wejściowe i wagi i oblicza wartość wyjściową:
Funkcja ocenyNeuralNetwork(inputVector, wagaVector)( var wynik = 0; inputVector.forEach(function(inputValue, wagaIndex) ( LayerValue = inputValue*weightVector; wynik += LayerValue; )); return (result.toFixed(2)); ) / / Może wydawać się skomplikowane, ale jedyne, co robi, to dopasowywanie par waga/dane wejściowe i dodanie wyniku
Zgodnie z oczekiwaniami, jeśli uruchomimy ten kod, otrzymamy taki sam wynik jak w naszym modelu lub wykresie...
EvaluateNeuralNetwork(wejścia, wagi); // 0,00
Przykład na żywo: Sieć neuronowa 001.
Kolejnym krokiem w ulepszaniu naszej sieci neuronowej będzie możliwość sprawdzenia własnej wartości wyjściowej lub wynikowych w sposób porównywalny z rzeczywistą sytuacją,
zakodujmy najpierw tę konkretną rzeczywistość w zmienną:

Aby wykryć niespójności (i ile ich jest), dodamy funkcję błędu:
Błąd = rzeczywistość – wyjście sieci neuronowej
Dzięki niemu możemy ocenić wydajność naszej sieci neuronowej:

Ale co ważniejsze, co z sytuacjami, w których rzeczywistość przynosi pozytywne rezultaty?

Teraz wiemy, że nasz model sieci neuronowej jest zepsuty (i wiemy w jakim stopniu), świetnie! Wspaniałe jest to, że możemy teraz używać funkcji błędu do kontrolowania naszego uczenia się. Ale wszystko to będzie miało sens, jeśli przedefiniujemy funkcję błędu w następujący sposób:
Błąd = Pożądane wyjście- Wyjście sieci neuronowej
Nieuchwytna, ale jakże istotna rozbieżność, po cichu pokazująca, że tak się stanie
wykorzystaj poprzednie wyniki do porównania z przyszłymi działaniami
(i do nauki, jak zobaczymy później). To istnieje również w prawdziwym życiu, pełnym
powtarzające się wzorce, więc może stać się strategią ewolucyjną (cóż, w
w większości przypadków).
Var wejście = ; var wagi = ; var pożądanyWynik = 1;
I nowa funkcja:
Funkcja validNeuralNetError(deired,actual) ( return (pożądany - aktualny); ) // Po ocenie zarówno sieci, jak i błędu otrzymamy: // "Wyjście sieci neuronowej: 0.00 Błąd: 1"
Przykład na żywo: Sieć neuronowa 002.
Podsumujmy. Zaczęliśmy od problemu, stworzyliśmy jego prosty model w postaci biologicznej sieci neuronowej i mieliśmy sposób na zmierzenie jego wydajności w porównaniu z rzeczywistością lub pożądanym rezultatem. Teraz musimy znaleźć sposób na skorygowanie tej rozbieżności. Jest to proces, który zarówno w przypadku komputerów, jak i ludzi można uznać za naukę.
Jak trenować sieć neuronową?
Podstawą uczenia zarówno biologicznych, jak i sztucznych sieci neuronowych jest powtarzanie
I algorytmy uczenia się, więc będziemy pracować z nimi oddzielnie. Zacznijmy
algorytmy szkoleniowe.
W naturze algorytmy uczenia się odnoszą się do zmian fizycznych lub chemicznych
charakterystyka neuronów po eksperymentach:

Dramatyczna ilustracja tego, jak dwa neurony zmieniają się w czasie w kodzie, oraz nasz model „algorytmu uczenia się” oznacza, że z biegiem czasu po prostu będziemy zmieniać pewne rzeczy, aby ułatwić nam życie. Dodajmy więc zmienną wskazującą, jak łatwe jest życie:
Var współczynnik uczenia się = 0,20; // Im większa wartość, tym szybszy będzie proces uczenia się :)
I co to zmieni?
Spowoduje to zmianę ciężarów (podobnie jak królika!), zwłaszcza masy wyjściowej, którą chcemy wyprodukować:

Sposób zakodowania takiego algorytmu zależy od Ciebie, dla uproszczenia do wagi dodam współczynnik uczenia, tutaj jest to w postaci funkcji:
Funkcja nauka(inputVector, wagaVector) ( wagaVector.forEach(funkcja(waga, indeks, wagi) ( if (inputVector > 0) ( wagi = waga + współczynnik uczenia; ) )); )
Gdy zostanie użyta, ta funkcja treningowa po prostu doda nasz współczynnik uczenia się do wektora wagi aktywny neuron, przed i po rundzie treningu (lub powtórzeniu), wyniki będą następujące:
// Oryginalny wektor wagi: // Wyjście sieci neuronowej: 0.00 Błąd: 1 nauka (wejście, wagi); // Nowy wektor wagi: // Wynik sieci neuronowej: 0,20 Błąd: 0,8 // Jeśli nie jest to oczywiste, wynik sieci neuronowej jest bliski 1 (wyjście kurczaka) - tego właśnie chcieliśmy, więc możemy stwierdzić, że się poruszamy w dobrym kierunku
Przykład na żywo: Sieć neuronowa 003.
OK, teraz, gdy zmierzamy we właściwym kierunku, ostatnim elementem tej układanki będzie wdrożenie powtórzenia.
Nie jest to aż tak skomplikowane, w naturze po prostu robimy to samo w kółko, ale w kodzie po prostu określamy liczbę powtórzeń:
próby Var = 6;
A implementacja funkcji liczby powtórzeń do naszej szkoleniowej sieci neuronowej będzie wyglądać następująco:
Ciąg funkcyjny(próby) ( for (i = 0; i< trials; i++) {
neuralNetResult = evaluateNeuralNetwork(input, weights);
learn(input, weights);
}
}
Oto nasz raport końcowy:
Wyjście sieci neuronowej: 0,00 Błąd: 1,00 Wektor wag: Wyjście sieci neuronowej: 0,20 Błąd: 0,80 Wektor wag: Wyjście sieci neuronowej: 0,40 Błąd: 0,60 Wektor wag: Wyjście sieci neuronowej: 0,60 Błąd: 0,40 Wektor wag: Wyjście sieci neuronowej: 0,80 Błąd : 0,20 Wektor wagi: Sieć neuronowa Wyjście: 1,00 Błąd: 0,00 Wektor wagi: // Obiad z kurczakiem !
Przykład na żywo: Sieć neuronowa 004.
Teraz mamy wektor wagi, który da tylko jeden wynik (kurczak na obiad), jeśli wektor wejściowy odpowiada rzeczywistości (kliknięcie trzeciego przycisku).
Jaka więc jest najfajniejsza rzecz, którą właśnie zrobiliśmy?
W tym konkretnym przypadku nasza sieć neuronowa (po treningu) potrafi rozpoznać dane wejściowe i powiedzieć, co doprowadzi do pożądanego rezultatu (będziemy jeszcze musieli zaprogramować określone sytuacje):

Dodatkowo jest to skalowalny model, zabawka i narzędzie do naszej nauki. Udało nam się dowiedzieć czegoś nowego na temat uczenia maszynowego, sieci neuronowych i sztucznej inteligencji.
Ostrzeżenie dla użytkowników:
- Nie ma mechanizmu przechowywania wyuczonych wag, więc ta sieć neuronowa zapomni wszystko, co wie. Aktualizując lub ponownie uruchamiając kod, potrzebujesz co najmniej sześciu udanych iteracji, aby sieć w pełni się nauczyła, jeśli myślisz, że osoba lub maszyna będzie losowo naciskać przyciski... To zajmie trochę czasu.
- Sieci biologiczne do uczenia się ważnych rzeczy mają współczynnik uczenia się równy 1, więc potrzebna byłaby tylko jedna udana iteracja.
- Istnieje algorytm uczenia się, który bardzo przypomina neurony biologiczne i ma chwytliwą nazwę: Reguła Widroffa-Hoffa, Lub Szkolenie Widroffa-Hoffa.
- Progi neuronalne (w naszym przykładzie 1) i efekty przekwalifikowania (przy dużej liczbie powtórzeń wynik będzie większy niż 1) nie są brane pod uwagę, ale mają charakter bardzo istotny i odpowiadają za duże i złożone bloki reakcji behawioralnych . Podobnie wagi ujemne.
Uwagi i lista odniesień do dalszej lektury
Próbowałem unikać matematyki i ścisłych terminów, ale jeśli jesteś zainteresowany, zbudowaliśmy perceptron, który jest zdefiniowany jako algorytm nadzorowanego uczenia się (uczenia nadzorowanego) podwójnych klasyfikatorów - ciężka sprawa.Biologiczna struktura mózgu nie jest tematem prostym, częściowo ze względu na nieprecyzyjność, a częściowo ze względu na jego złożoność. Lepiej zacząć od Neuroscience (Purves) i Cognitive Neuroscience (Gazzaniga). Zmodyfikowałem i zaadaptowałem przykład królika z Gateway to Memory (Gluck), który jest jednocześnie świetnym wprowadzeniem do świata wykresów.
Wprowadzenie do sieci neuronowych (Gurney) to kolejne świetne źródło informacji na temat wszystkich Twoich potrzeb w zakresie sztucznej inteligencji.
A teraz w Pythonie! Podziękowania dla Ilyi Andshmidt za udostępnienie wersji Pythona:
Dane wejściowe = wagi = pożądany_wynik = 1 współczynnik uczenia się = 0,2 prób = 6 def ocena_neural_network(input_array, waga_array): wynik = 0 dla i w zakresie (długość(input_array)): wartość_warstwy = tablica_wejściowa[i] * tablica_waga[i] wynik += wartość_warstwy print("evaluate_neural_network: " + str(result)) print("wagi: " + str(wagi)) zwróć wynik def Evaluate_error(pożądany, rzeczywisty): błąd = pożądany - aktualny print("evaluate_error: " + str(błąd) ) zwróć błąd def Learn(input_array,weight_array): print("learning...) for i in range(len(input_array)): if input_array[i] > 0: Weight_array[i] += learning_rate def train(trials ): dla i w zakresie (próby): neural_net_result = ocena_neural_network (wejścia, wagi) nauka (wejścia, wagi) pociąg (próby)
A teraz dalej! Dziękuję Kieranowi Maherowi za tę wersję.
Pakiet main import („fmt” „math”) func main() ( fmt.Println("Tworzenie danych wejściowych i wag ...") wejścia:= float64(0.00, 0.00, 1.00, 0.00) wagi:= float64(0.00, 0,00, 0,00, 0,00) pożądane:= 1,00 współczynnik uczenia się:= 0,20 prób:= 6 pociągów (próby, dane wejściowe, wagi, pożądane, współczynnik uczenia) ) func pociąg (próby int, wejścia float64, wagi float64, pożądane float64, naukaRate float64) ( dla i:= 1;< trials; i++ { weights = learn(inputs, weights, learningRate) output:= evaluate(inputs, weights) errorResult:= evaluateError(desired, output) fmt.Print("Output: ") fmt.Print(math.Round(output*100) / 100) fmt.Print("\nError: ") fmt.Print(math.Round(errorResult*100) / 100) fmt.Print("\n\n") } } func learn(inputVector float64, weightVector float64, learningRate float64) float64 { for index, inputValue:= range inputVector { if inputValue >0,00 ( wagaVector = wagaVector + learningRate ) zwróć wagęVector ) func ewaluuj(inputVector float64, wagaVector float64) float64 ( wynik:= 0,00 dla indeksu, inputValue:= zakres inputVector ( LayerValue:= inputValue * WeightVector wynik = wynik + LayerValue ) zwróć wynik ) func validError(pożądany float64, rzeczywisty float64) float64 (pożądany zwrot - rzeczywisty)
Możesz pomóc i przekazać część środków na rozwój strony
W związku z tym sieć neuronowa przyjmuje na wejściu dwie liczby i musi wyprowadzić inną liczbę – odpowiedź. Teraz o samych sieciach neuronowych.
Co to jest sieć neuronowa?
Sieć neuronowa to sekwencja neuronów połączonych synapsami. Struktura sieci neuronowej przyszła do świata programowania prosto z biologii. Dzięki takiej konstrukcji maszyna zyskuje możliwość analizowania, a nawet zapamiętywania różnych informacji. Sieci neuronowe potrafią nie tylko analizować napływające informacje, ale także odtwarzać je ze swojej pamięci. Dla zainteresowanych koniecznie obejrzyjcie 2 filmy z TED Talks: Wideo 1 , Wideo 2). Innymi słowy, sieć neuronowa jest maszynową interpretacją ludzkiego mózgu, który zawiera miliony neuronów przekazujących informacje w postaci impulsów elektrycznych.
Jakie są rodzaje sieci neuronowych?
Na razie rozważymy przykłady najbardziej podstawowego typu sieci neuronowych - sieci ze sprzężeniem zwrotnym (zwanej dalej siecią ze sprzężeniem zwrotnym). Również w kolejnych artykułach przedstawię więcej pojęć i opowiem o rekurencyjnych sieciach neuronowych. SPR, jak sama nazwa wskazuje, jest siecią o sekwencyjnym połączeniu warstw neuronowych, w której informacja przepływa zawsze tylko w jednym kierunku.
Do czego służą sieci neuronowe?
Sieci neuronowe służą do rozwiązywania złożonych problemów wymagających obliczeń analitycznych podobnych do tych, które wykonuje ludzki mózg. Najpopularniejszymi zastosowaniami sieci neuronowych są:
Klasyfikacja- rozkład danych według parametrów. Na przykład, jako dane wejściowe otrzymujesz zbiór osób i musisz zdecydować, której z nich przypisać zasługę, a której nie. Pracę tę może wykonać sieć neuronowa, analizując informacje takie jak wiek, wypłacalność, historia kredytowa itp.
Prognoza- umiejętność przewidzenia kolejnego kroku. Na przykład wzrost lub spadek akcji w zależności od sytuacji na giełdzie.
Uznanie- Obecnie najszerzej stosowane są sieci neuronowe. Używany w Google, gdy szukasz zdjęcia lub w aparatach telefonicznych, gdy wykrywa pozycję Twojej twarzy i podświetla ją i wiele więcej.
Aby teraz zrozumieć działanie sieci neuronowych, przyjrzyjmy się jej elementom i parametrom.
Co to jest neuron?
Neuron to jednostka obliczeniowa, która odbiera informacje, wykonuje na nich proste obliczenia i przesyła je dalej. Dzielą się na trzy główne typy: wejściowe (niebieskie), ukryte (czerwone) i wyjściowe (zielone). Istnieje również neuron przemieszczenia i neuron kontekstowy, o czym porozmawiamy w następnym artykule. W przypadku, gdy sieć neuronowa składa się z dużej liczby neuronów, wprowadza się termin warstwa. Odpowiednio istnieje warstwa wejściowa, która odbiera informacje, n warstw ukrytych (zwykle nie więcej niż 3), które je przetwarzają, oraz warstwa wyjściowa, która wysyła wynik. Każdy neuron ma 2 główne parametry: dane wejściowe i dane wyjściowe. W przypadku neuronu wejściowego: wejście=wyjście. W pozostałej części pole wejściowe zawiera całkowitą informację o wszystkich neuronach z poprzedniej warstwy, po czym jest normalizowane za pomocą funkcji aktywacji (na razie wyobraźmy sobie to jako f(x)) i trafia do pola wyjściowego.

Ważne do zapamiętaniaże neurony operują liczbami z zakresu lub [-1,1]. Ale jak, pytasz, przetwarzać liczby wykraczające poza ten zakres? W tym momencie najprostszą odpowiedzią jest podzielenie 1 przez tę liczbę. Proces ten nazywa się normalizacją i jest bardzo często stosowany w sieciach neuronowych. Więcej na ten temat nieco później.
Co to jest synapsa?

Synapsa to połączenie pomiędzy dwoma neuronami. Synapsy mają 1 parametr - wagę. Dzięki niemu informacja wejściowa zmienia się w trakcie przesyłania z jednego neuronu do drugiego. Załóżmy, że są 3 neurony, które przekazują informację kolejnemu. Mamy wtedy 3 wagi odpowiadające każdemu z tych neuronów. W przypadku neuronu, którego waga jest większa, informacja ta będzie dominować w kolejnym neuronie (na przykład mieszanie kolorów). Tak naprawdę zbiór wag sieci neuronowej, czyli macierz wag, jest swego rodzaju mózgiem całego układu. To dzięki tym wagom informacja wejściowa jest przetwarzana i przekształcana w wynik.
Ważne do zapamiętania, że podczas inicjalizacji sieci neuronowej wagi są rozmieszczone w losowej kolejności.
Jak działa sieć neuronowa?

Ten przykład pokazuje część sieci neuronowej, gdzie litery I oznaczają neurony wejściowe, litera H oznacza neuron ukryty, a litera w oznacza wagi. Ze wzoru wynika, że informacją wejściową jest suma wszystkich danych wejściowych pomnożona przez odpowiadające im wagi. Wtedy jako dane wejściowe podajemy 1 i 0. Niech w1=0,4 i w2 = 0,7 Dane wejściowe neuronu H1 będą następujące: 1*0,4+0*0,7=0,4. Teraz, gdy mamy już wejście, możemy uzyskać wyjście, podłączając wejście do funkcji aktywacji (więcej o tym później). Teraz, gdy mamy już wynik, przekazujemy go dalej. I tak powtarzamy dla wszystkich warstw, aż dotrzemy do neuronu wyjściowego. Po uruchomieniu takiej sieci po raz pierwszy przekonamy się, że odpowiedź jest daleka od poprawnej, ponieważ sieć nie jest trenowana. Aby poprawić wyniki będziemy ją szkolić. Zanim jednak dowiemy się, jak to zrobić, przedstawmy kilka terminów i właściwości sieci neuronowej.
Funkcja aktywacji
Funkcja aktywacji to sposób normalizacji danych wejściowych (mówiliśmy o tym wcześniej). Oznacza to, że jeśli masz na wejściu dużą liczbę, przepuszczając ją przez funkcję aktywacji, otrzymasz wynik w potrzebnym zakresie. Funkcji aktywacji jest całkiem sporo, dlatego rozważymy te najbardziej podstawowe: liniową, sigmoidalną (logistyczną) i tangens hiperboliczny. Ich główną różnicą jest zakres wartości.
Funkcja liniowa
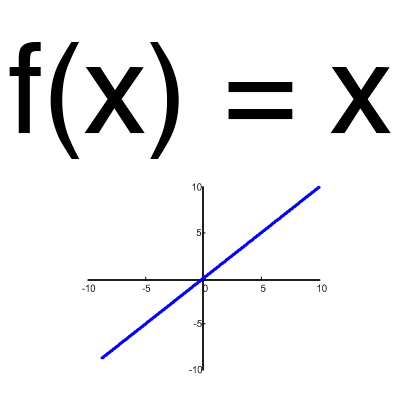
Ta funkcja prawie nigdy nie jest używana, z wyjątkiem sytuacji, gdy trzeba przetestować sieć neuronową lub przekazać wartość bez konwersji.
Sigmoidalny

Jest to najczęstsza funkcja aktywacji, a jej zakres wartości to . W tym miejscu pokazywana jest większość przykładów w Internecie i czasami nazywa się to funkcją logistyczną. Odpowiednio, jeśli w twoim przypadku występują wartości ujemne (na przykład akcje mogą rosnąć nie tylko w górę, ale także w dół), wówczas będziesz potrzebować funkcji, która przechwytuje również wartości ujemne.
Tangens hiperboliczny

Używanie tangensa hiperbolicznego ma sens tylko wtedy, gdy wartości mogą być zarówno ujemne, jak i dodatnie, ponieważ zakres funkcji wynosi [-1,1]. Nie zaleca się używania tej funkcji tylko z wartościami dodatnimi, ponieważ znacznie pogorszy to wyniki Twojej sieci neuronowej.
Zestaw treningowy
Zbiór szkoleniowy to sekwencja danych, na której działa sieć neuronowa. W naszym przypadku eliminacji lub (xor) mamy tylko 4 różne wyniki, czyli będziemy mieli 4 zbiory treningowe: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Iteracja
Jest to rodzaj licznika, który zwiększa się za każdym razem, gdy sieć neuronowa przechodzi przez jeden zestaw treningowy. Inaczej mówiąc, jest to całkowita liczba zestawów uczących ukończonych przez sieć neuronową.
era
Po inicjalizacji sieci neuronowej wartość ta jest ustawiana na 0, a górny limit jest ustawiany ręcznie. Im większa epoka, tym lepiej wyszkolona sieć i odpowiednio jej wynik. Epoka zwiększa się za każdym razem, gdy przechodzimy przez cały zestaw zestawów treningowych, w naszym przypadku 4 zestawy lub 4 iteracje.

Ważny nie myl iteracji z epoką i zrozum kolejność ich przyrostu. Pierwszy nr
gdy iteracja wzrasta, a następnie epoka, a nie odwrotnie. Innymi słowy, nie można najpierw trenować sieci neuronowej tylko w jednym zestawie, potem w drugim i tak dalej. Każdy zestaw musisz trenować raz na erę. W ten sposób można uniknąć błędów w obliczeniach.
Błąd
Błąd to procent odzwierciedlający różnicę między oczekiwaną a otrzymaną odpowiedzią. Błąd powstaje w każdej epoce i musi zaniknąć. Jeśli tak się nie stanie, oznacza to, że robisz coś złego. Błąd można obliczyć na różne sposoby, ale rozważymy tylko trzy główne metody: błąd średniokwadratowy (zwany dalej MSE), pierwiastek MSE i Arctan. Nie ma żadnych ograniczeń w użyciu, jak w przypadku funkcji aktywacji, i możesz wybrać dowolną metodę, która zapewni najlepsze rezultaty. Trzeba tylko pamiętać, że każda metoda inaczej zlicza błędy. W przypadku Arctana błąd będzie prawie zawsze większy, ponieważ działa na zasadzie: im większa różnica, tym większy błąd. Główny MSE będzie miał najmniejszy błąd, dlatego najczęściej używa się MSE, który utrzymuje równowagę w obliczaniu błędów.

Zrootuj MSE


Zasada obliczania błędów jest taka sama we wszystkich przypadkach. Dla każdego zestawu liczymy błąd, odejmując wynik od idealnej odpowiedzi. Następnie albo podnosimy ją do kwadratu, albo z tej różnicy obliczamy tangens kwadratowy, po czym otrzymaną liczbę dzielimy przez liczbę zbiorów.
Zadanie
Teraz, aby się sprawdzić, oblicz wyjście danej sieci neuronowej za pomocą sigmoidy i jej błąd za pomocą MSE.

Rozwiązanie
Wejście H1 = 1*0,45+0*-0,12=0,45
H1wyjście = sigmoida(0,45)=0,61H2wejście = 1*0,78+0*0,13=0,78
Wyjście H2 = sigmoida (0,78) = 0,69
O1ideał = 1 (0xor1=1)
Błąd = ((1-0,33)^2)/1=0,45
Dziękuję bardzo za uwagę! Mam nadzieję, że ten artykuł był dla Ciebie pomocny w badaniu sieci neuronowych. W następnym artykule opowiem o neuronach stronniczości i o tym, jak trenować sieć neuronową za pomocą propagacji wstecznej i opadania gradientowego.
Co to jest neuron przemieszczeniowy?

Zanim zaczniemy nasz główny temat, musimy wprowadzić koncepcję innego typu neuronu - neuronu przemieszczeniowego. Neuron przemieszczenia lub neuron polaryzacji to trzeci typ neuronu stosowany w większości sieci neuronowych. Osobliwością tego typu neuronów jest to, że ich wejście i wyjście są zawsze równe 1 i nigdy nie mają synaps wejściowych. Neurony przemieszczeniowe mogą być obecne w sieci neuronowej pojedynczo na warstwę lub całkowicie nieobecne; nie może to być 50/50 (na czerwono na schemacie zaznaczono wagi i neurony, których nie można rozmieścić). Połączenia neuronów polaryzacji są takie same jak w przypadku zwykłych neuronów - ze wszystkimi neuronami następnego poziomu, z tą różnicą, że między dwoma neuronami polaryzacji nie może być synaps. W związku z tym można je umieścić na warstwie wejściowej i wszystkich warstwach ukrytych, ale nie na warstwie wyjściowej, ponieważ po prostu nie będą miały z czym stworzyć połączenia.
Do czego służy neuron przemieszczeniowy?

Aby móc uzyskać wynik wyjściowy poprzez przesunięcie wykresu funkcji aktywacji w prawo lub w lewo, potrzebny jest neuron przemieszczeniowy. Jeśli brzmi to zawile, spójrzmy na prosty przykład, w którym istnieje jeden neuron wejściowy i jeden neuron wyjściowy. Następnie możemy ustalić, że produkcja O2 będzie równa wejściu H1, pomnożonemu przez jego wagę i przekazanemu przez funkcję aktywacji (wzór na zdjęciu po lewej stronie). W naszym konkretnym przypadku użyjemy sigmoidy.
Ze szkolnego kursu matematyki wiemy, że jeśli weźmiemy funkcję y = ax+b i zmienimy w niej wartości „a”, to zmieni się nachylenie funkcji (kolory linii na wykresie na w lewo), a jeśli zmienimy „b”, to przesuniemy funkcję w prawo lub w lewo (kolory linii na wykresie po prawej stronie). Zatem „a” jest wagą H1, a „b” jest wagą neuronu polaryzacji B1. To przybliżony przykład, ale mniej więcej tak to działa (jeśli spojrzysz na funkcję aktywacji po prawej stronie obrazu, zauważysz bardzo duże podobieństwo między formułami). Oznacza to, że podczas treningu dopasowujemy wagi neuronów ukrytych i wyjściowych, zmieniamy nachylenie funkcji aktywacji. Jednakże dostosowanie wagi neuronów polaryzacji może dać nam możliwość przesunięcia funkcji aktywacji wzdłuż osi X i wychwycenia nowych regionów. Innymi słowy, jeśli punkt odpowiedzialny za rozwiązanie znajduje się w miejscu pokazanym na wykresie po lewej stronie, wówczas sieć neuronowa nigdy nie będzie w stanie rozwiązać problemu bez użycia neuronów polaryzacyjnych. Dlatego rzadko można zobaczyć sieci neuronowe bez neuronów stronniczości.
Neurony przemieszczeniowe pomagają również w przypadku, gdy wszystkie neurony wejściowe otrzymują na wejściu wartość 0 i bez względu na to, jakie mają wagi, wszystkie przekażą 0 do następnej warstwy, ale nie w przypadku obecności neuronu przemieszczeniowego. Obecność lub brak neuronów stronniczości jest hiperparametrem (więcej o tym później). Krótko mówiąc, musisz sam zdecydować, czy chcesz użyć neuronów polaryzacyjnych, czy nie, uruchamiając NN z neuronami polaryzacyjnymi i bez nich i porównując wyniki.
WAŻNY należy pamiętać, że czasami neurony przemieszczeniowe nie są pokazane na diagramach, ale ich wagi są po prostu brane pod uwagę przy obliczaniu wartości wejściowej, na przykład:
wejście = H1*w1+H2*w2+b3
b3 = odchylenie*w3
Ponieważ jego wynik jest zawsze równy 1, możemy po prostu wyobrazić sobie, że mamy dodatkową synapsę z wagą i dodać tę wagę do sumy, nie wspominając o samym neuronie.
Jak sprawić, żeby NS dawał poprawne odpowiedzi?
Odpowiedź jest prosta – trzeba ją wyszkolić. Jednak niezależnie od tego, jak prosta jest odpowiedź, jej realizacja pod względem prostoty pozostawia wiele do życzenia. Metod nauczania sieci neuronowych jest kilka, ja wymienię 3, moim zdaniem, najciekawsze:
- Metoda wstecznej propagacji
- Metoda propagacji sprężystej lub Rprop
- Algorytm genetyczny
Rprop i GA zostaną omówione w innych artykułach, ale teraz przyjrzymy się podstawom - metodzie propagacji wstecznej, która wykorzystuje algorytm opadania gradientu.
Co to jest zejście gradientowe?
Jest to sposób na znalezienie lokalnego minimum lub maksimum funkcji poprzez poruszanie się wzdłuż gradientu. Jeśli rozumiesz koncepcję opadania gradientowego, nie powinieneś mieć żadnych pytań podczas korzystania z metody propagacji wstecznej. Najpierw dowiedzmy się, czym jest gradient i gdzie występuje w naszej sieci neuronowej. Zbudujmy wykres, w którym oś x pokaże wagę neuronu (w), a oś y pokaże błąd odpowiadający tej wadze (e).

Patrząc na ten wykres zrozumiemy, że wykres funkcji f(w) jest zależnością błędu od wybranej wagi. Na tym wykresie interesuje nas minimum globalne – punkt (w2,e2), czyli innymi słowy miejsce, w którym wykres znajduje się najbliżej osi x. Punkt ten będzie oznaczał, że wybierając wagę w2 otrzymamy najmniejszy błąd – e2 i w konsekwencji najlepszy wynik ze wszystkich możliwych. W znalezieniu tego punktu pomoże nam metoda gradientowego opadania (na wykresie gradient jest zaznaczony na żółto). W związku z tym każda waga w sieci neuronowej będzie miała swój własny wykres i gradient, a dla każdego konieczne jest znalezienie globalnego minimum.
Czym więc jest ten gradient? Gradient to wektor określający nachylenie zbocza i wskazujący jego kierunek względem dowolnego punktu na powierzchni lub wykresie. Aby znaleźć gradient należy wziąć pochodną wykresu w danym punkcie (jak pokazano na wykresie). Kierując się w stronę tego nachylenia, będziemy płynnie zsuwać się w dolinę. Teraz wyobraź sobie, że błędem jest narciarz, a wykresem funkcji jest góra. Odpowiednio, jeśli błąd wynosi 100%, narciarz znajduje się na samym szczycie góry, a jeśli błąd wynosi 0%, to na dole. Jak wszyscy narciarze, błąd stara się jak najszybciej zejść i zmniejszyć jego wartość. Ostatecznie powinniśmy uzyskać następujący wynik:

Wyobraź sobie, że narciarz zostaje wyrzucony helikopterem na górę. To, jak wysokie lub niskie, zależy od przypadku (podobnie jak w sieci neuronowej, podczas inicjalizacji wagi są umieszczane w losowej kolejności). Powiedzmy, że błąd wynosi 90% i to jest nasz punkt wyjścia. Teraz narciarz musi zjechać w dół po pochyłości. Schodząc, w każdym punkcie obliczymy nachylenie, które wskaże nam kierunek zjazdu, a gdy nachylenie się zmieni, skorygujemy je. Jeśli zbocze jest proste, to po n-tej liczbie takich działań dotrzemy do niziny. Jednak w większości przypadków nachylenie (wykres funkcji) będzie pofalowane i nasz narciarz stanie przed bardzo poważnym problemem – lokalnym minimum. Myślę, że każdy wie, co to jest minimum lokalne i globalne funkcji, dla odświeżenia pamięci oto przykład. Dotarcie do minimum lokalnego jest obarczone tym, że nasz narciarz na zawsze pozostanie na tej nizinie i nigdy nie zjedzie z góry, dlatego nigdy nie uda nam się uzyskać prawidłowej odpowiedzi. Możemy jednak tego uniknąć wyposażając naszego narciarza w plecak odrzutowy zwany pędem. Oto krótka ilustracja tej chwili:

Jak już zapewne się domyślacie, plecak ten zapewni narciarzowi przyspieszenie niezbędne do pokonania wzniesienia, które utrzymuje nas w lokalnym minimum, jednak tutaj jest jedno ALE. Wyobraźmy sobie, że ustawiliśmy pewną wartość parametru momentu i bez problemu udało nam się pokonać wszystkie lokalne minima i osiągnąć minimum globalne. Ponieważ nie możemy po prostu wyłączyć plecaka odrzutowego, możemy pominąć globalne minimum, jeśli w jego pobliżu nadal znajdują się minima. W ostatecznym przypadku nie jest to takie istotne, bo prędzej czy później i tak wrócimy do globalnego minimum, warto jednak pamiętać, że im większy moment, tym większy zakres, z jakim narciarz będzie jeździł na nizinach. Wraz z momentem metoda propagacji wstecznej wykorzystuje również taki parametr, jak szybkość uczenia się. Jak wielu zapewne pomyśli, im większa prędkość uczenia się, tym szybciej będziemy trenować sieć neuronową. NIE. Szybkość uczenia się, podobnie jak moment obrotowy, to hiperparametr — wartość wybierana metodą prób i błędów. Szybkość nauki można bezpośrednio powiązać z szybkością narciarza i śmiało możemy powiedzieć, że im dalej zajedziesz, tym ciszej będziesz jechał. Jednak i tu są pewne aspekty, bo jeśli w ogóle nie damy narciarzowi żadnej prędkości, to w ogóle nigdzie nie pojedzie, a jeśli damy mu małą prędkość, to czas podróży może się bardzo rozciągnąć , bardzo długi okres czasu. Co się wtedy stanie, jeśli nadamy za dużą prędkość?

Jak widać nic dobrego. Narciarz zacznie zsuwać się na złą ścieżkę, a może nawet w przeciwnym kierunku, co, jak rozumiesz, tylko oddala nas od znalezienia prawidłowej odpowiedzi. Dlatego we wszystkich tych parametrach konieczne jest znalezienie złotego środka, aby uniknąć braku zbieżności NS (o tym nieco później).
Co to jest metoda propagacji wstecznej (BPM)?
Teraz dotarliśmy do punktu, w którym możemy omówić, w jaki sposób upewnić się, że Twój NS może uczyć się poprawnie i podejmować właściwe decyzje. MPA jest bardzo dobrze zwizualizowane na tym GIF-ie:

Przyjrzyjmy się teraz szczegółowo każdemu etapowi. Jeśli pamiętasz, w poprzednim artykule obliczyliśmy moc wyjściową NS. Inaczej nazywa się to przejściem w przód, co oznacza, że sekwencyjnie przekazujemy informacje z neuronów wejściowych do neuronów wyjściowych. Po czym obliczamy błąd i na jego podstawie wykonujemy transmisję odwrotną, która polega na sekwencyjnej zmianie wag sieci neuronowej, zaczynając od wag neuronu wyjściowego. Wartość skali będzie się zmieniać w kierunku, który da nam najlepszy wynik. W moich obliczeniach użyję metody znajdowania delty, ponieważ jest to najprostsza i najbardziej zrozumiała metoda. Do aktualizacji wag użyję także metody stochastycznej (więcej o tym później).
Kontynuujmy teraz obliczenia od miejsca, w którym zakończyliśmy obliczenia w poprzednim artykule.
Dane zadania z poprzedniego artykułu
Dane: I1=1, I2=0, w1=0,45, w2=0,78,w3=-0,12,w4=0,13,w5=1,5,w6=-2,3.
Wejście H1 = 1*0,45+0*-0,12=0,45
Wyjście H1 = sigmoida (0,45) = 0,61
Wejście H2 = 1*0,78+0*0,13=0,78
Wyjście H2 = sigmoida (0,78) = 0,69
Wejście O1 = 0,61*1,5+0,69*-2,3=-0,672
Wyjście O1 = sigmoida(-0,672)=0,33
O1ideał = 1 (0xor1=1)
Błąd = ((1-0,33)^2)/1=0,45
Wynik - 0,33, błąd - 45%.
Ponieważ obliczyliśmy już wynik NN i jego błąd, możemy od razu przystąpić do MOP. Jak wspomniałem wcześniej, algorytm zawsze zaczyna się od neuronu wyjściowego. W tym przypadku obliczmy dla niego wartość δ (delta) korzystając ze wzoru 1.  Ponieważ neuron wyjściowy nie ma synaps wychodzących, zastosujemy pierwszy wzór (wyjście δ), dlatego dla neuronów ukrytych zastosujemy już drugi wzór (δ ukryty). Tutaj wszystko jest dość proste: obliczamy różnicę między wynikiem pożądanym a uzyskanym i mnożymy ją przez pochodną funkcji aktywacji od wartości wejściowej danego neuronu. Zanim zaczniemy obliczenia, chcę zwrócić uwagę na pochodną. Po pierwsze, jak już zapewne stało się jasne, w przypadku MOR konieczne jest stosowanie tylko tych funkcji aktywacji, które można rozróżnić. Po drugie, aby uniknąć niepotrzebnych obliczeń, wzór na pochodną można zastąpić bardziej przyjaznym i prostszym wzorem w postaci:
Ponieważ neuron wyjściowy nie ma synaps wychodzących, zastosujemy pierwszy wzór (wyjście δ), dlatego dla neuronów ukrytych zastosujemy już drugi wzór (δ ukryty). Tutaj wszystko jest dość proste: obliczamy różnicę między wynikiem pożądanym a uzyskanym i mnożymy ją przez pochodną funkcji aktywacji od wartości wejściowej danego neuronu. Zanim zaczniemy obliczenia, chcę zwrócić uwagę na pochodną. Po pierwsze, jak już zapewne stało się jasne, w przypadku MOR konieczne jest stosowanie tylko tych funkcji aktywacji, które można rozróżnić. Po drugie, aby uniknąć niepotrzebnych obliczeń, wzór na pochodną można zastąpić bardziej przyjaznym i prostszym wzorem w postaci: 
Zatem nasze obliczenia dla punktu O1 będą wyglądać następująco.
Rozwiązanie
To kończy obliczenia dla neuronu O1. Pamiętaj, że po obliczeniu delty neuronu należy natychmiast zaktualizować wagi wszystkich synaps wychodzących tego neuronu. Ponieważ w przypadku O1 ich nie ma, przechodzimy do neuronów poziomu ukrytego i robimy to samo, z tą różnicą, że mamy już drugi wzór na obliczenie delty i jego istotą jest pomnożenie pochodnej funkcji aktywacji od wartości wejściowej przez sumę iloczynów wszystkich wychodzących wag i delty neuronu, z którym połączona jest ta synapsa. Ale dlaczego formuły są różne? Faktem jest, że cały sens MOR polega na rozłożeniu błędu neuronów wyjściowych na wszystkie wagi NN. Błąd można obliczyć tylko na poziomie wyjściowym, tak jak już to zrobiliśmy, obliczyliśmy także deltę, w której ten błąd już istnieje. W związku z tym teraz zamiast błędu użyjemy delty, która będzie przekazywana z neuronu na neuron. W tym przypadku znajdźmy deltę dla H1:
Rozwiązanie
Wyjście H1 = 0,61
w5 = 1,5
δO1 = 0,148δH1 = ((1 - 0,61) * 0,61) * (1,5 * 0,148) = 0,053
Teraz musimy znaleźć gradient dla każdej wychodzącej synapsy. Tutaj zwykle wstawiają ułamek 3-piętrowy z mnóstwem pochodnych i innym matematycznym piekłem, ale na tym polega piękno stosowania metody liczenia delta, ponieważ ostatecznie wzór na znalezienie gradientu będzie wyglądał następująco:
Tutaj punkt A jest punktem na początku synapsy, a punkt B na końcu synapsy. Możemy więc obliczyć gradient w5 w następujący sposób:
Rozwiązanie
Mamy teraz wszystkie niezbędne dane do aktualizacji wagi w5 i zrobimy to dzięki funkcji MOP, która oblicza o ile należy zmienić tę lub inną wagę i wygląda to tak: 
Zdecydowanie radzę nie ignorować drugiej części wyrażenia i wykorzystywać moment, gdyż pozwoli to uniknąć problemów z minimum lokalnym.
Widzimy tutaj 2 stałe, o których już mówiliśmy, przyglądając się algorytmowi opadania gradientu: E (epsilon) to szybkość uczenia się, α (alfa) to moment. Przekładając wzór na słowa, otrzymujemy: zmiana wagi synapsy jest równa współczynnikowi szybkości uczenia się pomnożonemu przez gradient tej wagi, dodajemy moment pomnożony przez poprzednią zmianę tej wagi (przy 1. iteracji jest to 0). W tym przypadku obliczmy zmianę ciężaru w5 i zaktualizujmy jej wartość dodając do niej Δw5.
Rozwiązanie
Zatem po zastosowaniu algorytmu nasza waga wzrosła o 0,063. Teraz sugeruję, abyś zrobił to samo dla H2.
Rozwiązanie
I oczywiście nie zapomnij o I1 i I2, ponieważ one również mają synapsy, których wagi również musimy zaktualizować. Należy jednak pamiętać, że nie musimy znajdować delt dla neuronów wejściowych, ponieważ nie mają one synaps wejściowych.
Rozwiązanie
Teraz upewnijmy się, że zrobiliśmy wszystko poprawnie i ponownie obliczmy wyjście sieci neuronowej tylko ze zaktualizowanymi wagami.
Rozwiązanie
Jak widać po jednej iteracji MOP udało nam się zredukować błąd o 0,04 (6%). Teraz musisz to powtarzać w kółko, aż błąd będzie wystarczająco mały.
Co jeszcze musisz wiedzieć o procesie uczenia się?
Sieć neuronową można trenować z nauczycielem lub bez niego (uczenie nadzorowane, bez nadzoru).
Szkolenie z korepetytorem- jest to rodzaj treningu nieodłącznie związany z takimi zagadnieniami jak regresja i klasyfikacja (użyliśmy go w przykładzie podanym powyżej). Innymi słowy, tutaj pełnisz rolę nauczyciela, a NS jako ucznia. Podajesz dane wejściowe i pożądany rezultat, to znaczy uczeń, patrząc na dane wejściowe, zrozumie, że musi dążyć do wyniku, który mu zapewniłeś.
Uczenie się bez nadzoru- tego typu szkolenia nie zdarzają się zbyt często. Nie ma tu nauczyciela, więc sieć nie osiąga pożądanego rezultatu lub jest ich bardzo mało. Zasadniczo ten rodzaj uczenia jest nieodłącznym elementem sieci neuronowych, których zadaniem jest grupowanie danych według określonych parametrów. Załóżmy, że przesyłasz 10 000 artykułów na temat Habré i po przeanalizowaniu wszystkich tych artykułów NS będzie w stanie podzielić je na kategorie na podstawie, na przykład, często występujących słów. Artykuły, w których wspomina się o językach programowania, o programowaniu i gdzie są słowa takie jak Photoshop, o projektowaniu.
Istnieje również tak interesująca metoda jak uczenie się przez wzmacnianie(uczenie się przez wzmacnianie). Metoda ta zasługuje na osobny artykuł, ale postaram się pokrótce opisać jej istotę. Metodę tę można zastosować wtedy, gdy na podstawie wyników otrzymanych z NS możemy ją ocenić. Na przykład chcemy nauczyć NS grać w PAC-MANA, a wtedy za każdym razem, gdy NS zdobędzie dużo punktów, będziemy ją zachęcać. Innymi słowy, dajemy NS prawo do znalezienia dowolnej drogi do osiągnięcia celu, o ile przyniesie to dobry wynik. W ten sposób sieć zaczyna rozumieć, co chce dzięki niej osiągnąć i stara się znaleźć najlepszy sposób na osiągnięcie tego celu, bez ciągłego dostarczania danych od „nauczyciela”.
Trening można również przeprowadzić trzema metodami: metodą stochastyczną, metodą wsadową i metodą mini-batch. Artykułów i badań na temat tego, która metoda jest najlepsza, jest tak wiele, że nikt nie potrafi udzielić ogólnej odpowiedzi. Jestem zwolennikiem metody stochastycznej, ale nie przeczę, że każda metoda ma swoje wady i zalety.
Krótko o każdej metodzie:
Stochastyczny(czasami nazywa się to również online) metoda działa na następującej zasadzie - znajdź Δw, natychmiast zaktualizuj odpowiednią wagę.
Metoda wsadowa to działa inaczej. Sumujemy Δw wszystkich wag w bieżącej iteracji i dopiero wtedy aktualizujemy wszystkie wagi, korzystając z tej sumy. Jedną z najważniejszych zalet tego podejścia jest znaczna oszczędność czasu obliczeń, ale w tym przypadku może to znacznie wpłynąć na dokładność.
Metoda mini-partii jest złotym środkiem i stara się połączyć zalety obu metod. Zasada jest taka: dowolnie rozdzielamy wagi pomiędzy grupy i zmieniamy ich wagi o sumę Δw wszystkich wag w danej grupie.
Co to są hiperparametry?
Hiperparametry to wartości, które należy dobierać ręcznie i często metodą prób i błędów. Wśród tych wartości są:
- Moment i szybkość nauki
- Liczba ukrytych warstw
- Liczba neuronów w każdej warstwie
- Obecność lub brak neuronów przemieszczeniowych
Inne typy sieci neuronowych zawierają dodatkowe hiperparametry, ale nie będziemy o nich rozmawiać. Wybór odpowiednich hiperparametrów jest bardzo ważny i będzie miał bezpośredni wpływ na zbieżność Twojej sieci NN. Dość łatwo jest zrozumieć, czy warto stosować neurony przemieszczeniowe, czy nie. Liczbę ukrytych warstw i znajdujących się w nich neuronów można obliczyć brutalną siłą w oparciu o jedną prostą zasadę – im więcej neuronów, tym dokładniejszy wynik i wykładniczo dłuższy czas poświęcony na jego trenowanie. Warto jednak pamiętać, że nie należy tworzyć sieci neuronowej z 1000 neuronów do rozwiązywania prostych problemów. Ale przy wyborze momentu i szybkości nauki wszystko jest trochę bardziej skomplikowane. Te hiperparametry będą się różnić w zależności od wykonywanego zadania i architektury sieci neuronowej. Na przykład w przypadku rozwiązania XOR szybkość uczenia się może mieścić się w zakresie 0,3–0,7, ale w sieci neuronowej, która analizuje i przewiduje ceny akcji, szybkość uczenia powyżej 0,00001 prowadzi do słabej zbieżności sieci neuronowej. Nie powinieneś teraz skupiać swojej uwagi na hiperparametrach i starać się dokładnie zrozumieć, jak je wybrać. Przyjdzie to z doświadczeniem, ale na razie radzę po prostu eksperymentować i szukać przykładów rozwiązania konkretnego problemu w Internecie.
Co to jest konwergencja?

Zbieżność wskazuje, czy architektura NN jest poprawna i czy hiperparametry zostały dobrane prawidłowo zgodnie z zadaniem. Załóżmy, że nasz program wyświetla błąd NS przy każdej iteracji w dzienniku. Jeśli błąd maleje z każdą iteracją, to jesteśmy na dobrej drodze i nasza NN jest zbieżna. Jeśli błąd skacze w górę i w dół lub zawiesza się na pewnym poziomie, wówczas NN nie jest zbieżny. W 99% przypadków rozwiązuje się to poprzez zmianę hiperparametrów. Pozostały 1% będzie oznaczać, że masz błąd w architekturze sieci neuronowej. Zdarza się również, że na zbieżność wpływa przeuczenie sieci neuronowej.
Co to jest przekwalifikowanie?
Overfitting, jak sama nazwa wskazuje, to stan sieci neuronowej, gdy jest ona przesycona danymi. Ten problem występuje, jeśli zbyt długo uczysz sieć na tych samych danych. Innymi słowy, sieć zacznie nie uczyć się na danych, ale je zapamiętywać i „wkuwać”. W związku z tym po przesłaniu nowych danych na wejście tej sieci neuronowej w otrzymanych danych może pojawić się szum, co wpłynie na dokładność wyniku. Na przykład, jeśli pokażemy NS różne zdjęcia jabłek (tylko czerwone) i powiemy, że to jest jabłko. Wtedy, gdy NN zobaczy żółte lub zielone jabłko, nie będzie w stanie określić, czy jest to jabłko, ponieważ przypomniała sobie, że wszystkie jabłka muszą być czerwone. I odwrotnie, gdy NN zobaczy coś czerwonego i mającego kształt jabłka, np. brzoskwini, powie, że to jabłko. To jest hałas. Na wykresie szum będzie wyglądał następująco.

Można zauważyć, że wykres funkcji zmienia się znacznie w zależności od punktu, co stanowi dane wyjściowe (wynik) naszej NN. Idealnie byłoby, gdyby ten wykres był mniej falisty i prosty. Aby uniknąć przetrenowania, nie należy trenować sieci neuronowej przez dłuższy czas na tych samych lub bardzo podobnych danych. Ponadto nadmierne dopasowanie może być spowodowane dużą liczbą parametrów dostarczanych na wejście sieci neuronowej lub zbyt złożoną architekturą. Zatem, jeśli po fazie uczenia zauważysz błędy (szumy) na wyjściu, powinieneś zastosować jedną z metod regularyzacji, ale w większości przypadków nie będzie to konieczne.



