Dobré odpoledne, jmenuji se Natalia Efremová a jsem vědecká pracovnice v NtechLab. Dnes budu hovořit o typech neuronových sítí a jejich aplikacích.
Nejprve řeknu pár slov o naší společnosti. Společnost je nová, možná mnozí z vás ještě neví, co děláme. Minulý rok jsme vyhráli soutěž MegaFace. Jedná se o mezinárodní soutěž v rozpoznávání obličeje. V témže roce byla otevřena i naše firma, to znamená, že jsme na trhu asi rok, i o něco více. V souladu s tím jsme jednou z předních společností v oblasti rozpoznávání obličeje a zpracování biometrických snímků.
První část mé zprávy bude zaměřena na ty, kteří neznají neuronové sítě. Přímo se podílím na hlubokém učení. V tomto oboru pracuji více než 10 let. Ačkoli se objevil o něco méně než před deseti lety, dříve existovaly určité základy neuronových sítí, které byly podobné systému hlubokého učení.
Za posledních 10 let se hluboké učení a počítačové vidění vyvíjely neuvěřitelným tempem. Vše, co bylo v této oblasti významné, se stalo za posledních 6 let.
Budu mluvit o praktických aspektech: kde, kdy, co použít z hlediska hlubokého učení pro zpracování obrazu a videa, pro rozpoznávání obrazu a obličeje, protože pracuji ve společnosti, která to dělá. Řeknu vám něco o rozpoznávání emocí a o tom, jaké přístupy se používají ve hrách a robotice. Budu také mluvit o nestandardní aplikaci hlubokého učení, o něčem, co z vědeckých institucí teprve vzniká a v praxi se stále málo využívá, jak se dá aplikovat a proč je těžké aplikovat.
Zpráva se bude skládat ze dvou částí. Protože většina z nich je obeznámena s neuronovými sítěmi, nejprve rychle popíšu, jak fungují neuronové sítě, co jsou biologické neuronové sítě, proč je pro nás důležité vědět, jak fungují, co jsou umělé neuronové sítě a jaké architektury se v jakých oblastech používají. .
Okamžitě se omlouvám, přeskočím trochu k anglické terminologii, protože většinu z toho, jak se tomu říká rusky, ani nevím. Možná i vy.
První část zprávy bude tedy věnována konvolučním neuronovým sítím. Řeknu vám, jak funguje konvoluční neuronová síť (CNN) a rozpoznávání obrazu na příkladu z rozpoznávání obličeje. Řeknu vám něco o rekurentních neuronových sítích (RNN) a posílení učení na příkladu systémů hlubokého učení.
Jako nestandardní aplikaci neuronových sítí budu mluvit o tom, jak CNN funguje v medicíně na rozpoznávání voxelových obrázků, jak se neuronové sítě používají k rozpoznání chudoby v Africe.
Co jsou to neuronové sítě
Prototyp pro vytváření neuronových sítí byly, kupodivu, biologické neuronové sítě. Mnozí z vás možná vědí, jak programovat neuronovou síť, ale kde se to vzalo, myslím, že někteří nevědí. Dvě třetiny všech smyslových informací, které k nám přicházejí, pochází ze zrakových orgánů vnímání. Více než jednu třetinu povrchu našeho mozku zabírají dvě nejdůležitější zrakové oblasti – dorzální zraková dráha a ventrální zraková dráha.Dorzální zraková dráha začíná v primární zrakové zóně, na naší temeni, a pokračuje vzhůru, zatímco ventrální dráha začíná v zadní části naší hlavy a končí přibližně za ušima. Všechno důležité rozpoznávání vzorů, které se nám děje, vše, co nese význam, který si uvědomujeme, se odehrává přímo tam, za ušima.
Proč je to důležité? Protože je často nutné porozumět neuronovým sítím. Za prvé o tom všichni mluví a já už jsem si na to zvykl, a za druhé je fakt, že všechny oblasti, které se v neuronových sítích používají pro rozpoznávání obrazu, k nám přišly právě z ventrální zrakové dráhy, kde každá zóna je zodpovědná za její přesně definovanou funkci.
Obraz k nám přichází ze sítnice, prochází řadou zrakových zón a končí v časové zóně.
Ve vzdálených 60. letech minulého století, kdy studium vizuálních oblastí mozku teprve začínalo, byly první experimenty prováděny na zvířatech, protože neexistovala žádná fMRI. Mozek byl studován pomocí elektrod implantovaných do různých vizuálních oblastí.
První vizuální oblast studovali David Hubel a Thorsten Wiesel v roce 1962. Prováděli pokusy na kočkách. Kočkám byly ukázány různé pohyblivé předměty. Na co mozkové buňky reagovaly, byl podnět, který zvíře rozpoznalo. I nyní se těmito drakonickými způsoby provádí mnoho experimentů. Ale přesto je to nejúčinnější způsob, jak zjistit, co dělá každá malá buňka v našem mozku.
Stejně tak bylo objeveno mnohem více důležitých vlastností vizuálních oblastí, které nyní využíváme v hlubokém učení. Jednou z nejdůležitějších vlastností je zvětšení receptivních polí našich buněk při přechodu z primárních zrakových oblastí do temporálních laloků, tedy pozdějších zrakových oblastí. Receptivní pole je ta část obrazu, kterou zpracovává každá buňka našeho mozku. Každá buňka má své vlastní receptivní pole. Stejná vlastnost je zachována v neuronových sítích, jak asi všichni víte.
S přibývajícími receptivními poli se také zvyšují komplexní podněty, které neuronové sítě obvykle rozpoznávají.

Zde vidíte příklady složitosti podnětů, různých dvourozměrných tvarů, které jsou rozpoznávány v oblastech V2, V4 a různých částech časových polí u opic makaků. Provádí se také řada MRI experimentů.

Zde se můžete podívat, jak takové experimenty probíhají. Jedná se o 1 nanometrovou část IT kortexových zón opice při rozpoznávání různých objektů. Kde je rozpoznána, je zvýrazněno.
Pojďme si to shrnout. Důležitou vlastností, kterou chceme z vizuálních oblastí přijmout, je to, že se zvětšuje velikost receptivních polí a zvyšuje se složitost objektů, které rozpoznáváme.
Počítačové vidění
Než jsme se to naučili aplikovat na počítačové vidění, obecně to jako takové neexistovalo. V každém případě to nefungovalo tak dobře, jako to funguje nyní.Všechny tyto vlastnosti přeneseme do neuronové sítě a nyní to funguje, pokud nezahrnete malou odbočku k datovým sadám, o kterých budu mluvit později.
Nejprve ale něco málo o nejjednodušším perceptronu. Tvoří se také podle obrazu a podoby našeho mozku. Nejjednodušším prvkem připomínajícím mozkovou buňku je neuron. Obsahuje vstupní prvky, které jsou ve výchozím nastavení uspořádány zleva doprava, občas zdola nahoru. Vlevo jsou vstupní části neuronu, vpravo výstupní části neuronu.
Nejjednodušší perceptron je schopen provádět pouze ty nejjednodušší operace. Abychom mohli provádět složitější výpočty, potřebujeme strukturu s více skrytými vrstvami.

V případě počítačového vidění potřebujeme ještě více skrytých vrstev. A teprve potom systém smysluplně rozpozná, co vidí.
Řeknu vám tedy, co se děje během rozpoznávání obrazu na příkladu tváří.
Abychom se podívali na tento obrázek a řekli, že ukazuje přesně tvář sochy, je docela jednoduché. Před rokem 2010 to však byl pro počítačové vidění neuvěřitelně obtížný úkol. Kdo se touto problematikou zabýval před touto dobou, asi ví, jak těžké bylo beze slov popsat předmět, který chceme na obrázku najít.
Potřebovali jsme to udělat nějakým geometrickým způsobem, popsat objekt, popsat vztahy objektu, jak spolu tyto části mohou souviset, pak najít tento obrázek na objektu, porovnat je a získat to, co jsme špatně poznali. Obvykle to bylo o něco lepší než si hodit mincí. O něco lepší než náhoda.
Takhle to teď nefunguje. Náš obrázek rozdělujeme buď na pixely, nebo na určité záplaty: 2x2, 3x3, 5x5, 11x11 pixelů - jak je vhodné pro tvůrce systému, ve kterém slouží jako vstupní vrstva do neuronové sítě.
Signály z těchto vstupních vrstev jsou přenášeny z vrstvy do vrstvy pomocí synapsí, přičemž každá vrstva má své vlastní specifické koeficienty. Takže přecházíme z vrstvy do vrstvy, z vrstvy do vrstvy, dokud nedosáhneme, že jsme poznali obličej.
Obvykle lze všechny tyto části rozdělit do tří tříd, budeme je označovat X, W a Y, kde X je náš vstupní obrázek, Y je sada štítků a potřebujeme získat naše váhy. Jak vypočítáme W?
Vzhledem k našim X a Y se to zdá jednoduché. To, co je však označeno hvězdičkou, je velmi složitá nelineární operace, která bohužel nemá inverzní. I se 2 danými složkami rovnice je velmi obtížné ji vypočítat. Musíme se tedy postupně metodou pokus-omyl, volbou váhy W, přesvědčit, aby se chyba co nejvíce zmenšila, nejlépe tak, aby byla rovna nule.

Tento proces probíhá iterativně, neustále snižujeme, dokud nenajdeme hodnotu hmotnosti W, která nám dostatečně vyhovuje.
Mimochodem, ani jedna neuronová síť, se kterou jsem pracoval, nedosáhla chyby rovné nule, ale fungovalo to docela dobře.

Jedná se o první síť, která vyhrála mezinárodní soutěž ImageNet v roce 2012. Jedná se o tzv. AlexNet. Toto je síť, která jako první prohlásila, že existují konvoluční neuronové sítě, a od té doby se konvoluční neuronové sítě nikdy nevzdaly svých pozic ve všech mezinárodních soutěžích.
Navzdory tomu, že je tato síť poměrně malá (má pouze 7 skrytých vrstev), obsahuje 650 tisíc neuronů s 60 miliony parametrů. Abychom se iterativně naučili najít potřebné váhy, potřebujeme spoustu příkladů.
Neuronová síť se učí na příkladu obrázku a štítku. Stejně jako nás v dětství učili „toto je kočka a toto je pes“, neuronové sítě jsou trénovány na velkém množství obrázků. Faktem ale je, že do roku 2010 neexistoval žádný dostatečně velký soubor dat, který by dokázal takové množství parametrů naučit rozpoznávat obrázky.
Největší databáze, které existovaly před touto dobou, byly PASCAL VOC, který měl pouze 20 kategorií objektů, a Caltech 101, který byl vyvinut na California Institute of Technology. Ta poslední měla 101 kategorií, a to bylo hodně. Ti, kteří nebyli schopni najít své objekty v žádné z těchto databází, museli stát své databáze, což, řeknu, je strašně bolestivé.
V roce 2010 se však objevila databáze ImageNet, která obsahovala 15 milionů obrázků, rozdělených do 22 tisíc kategorií. To vyřešilo náš problém trénování neuronových sítí. Nyní může každý, kdo má akademickou adresu, snadno přejít na webovou stránku základny, požádat o přístup a získat tuto základnu pro trénování svých neuronových sítí. Reagují celkem rychle, dle mého názoru, druhý den.
Ve srovnání s předchozími datovými soubory se jedná o velmi rozsáhlou databázi.

Příklad ukazuje, jak bezvýznamné bylo vše, co tomu předcházelo. Současně se základnou ImageNet se objevila soutěž ImageNet, mezinárodní výzva, které se mohou zúčastnit všechny týmy, které chtějí soutěžit.
Vítězná síť letos vznikla v Číně, měla 269 vrstev. Nevím, kolik parametrů je, mám podezření, že je jich také hodně.
Architektura hluboké neuronové sítě
Obvykle se dá rozdělit na 2 části: ty, kteří studují, a ty, kteří nestudují.
Černá označuje ty části, které se neučí, všechny ostatní vrstvy jsou schopné se učit. Existuje mnoho definic toho, co je uvnitř každé konvoluční vrstvy. Jednou z přijatých notací je, že jedna vrstva se třemi složkami je rozdělena na konvoluční fázi, detektorovou fázi a sdružovací fázi.
Nebudu zabíhat do podrobností; bude mnohem více zpráv, které budou podrobně diskutovat o tom, jak to funguje. Řeknu vám to na příkladu.
Jelikož mě pořadatelé požádali, abych mnoho vzorců nezmiňoval, úplně jsem je vyhodil.

Vstupní obraz tedy spadá do sítě vrstev, které lze nazvat filtry různých velikostí a různé složitosti prvků, které rozpoznávají. Tyto filtry tvoří svůj vlastní index nebo sadu funkcí, které pak přejdou do klasifikátoru. Obvykle je to buď SVM nebo MLP - vícevrstvý perceptron, podle toho, co je pro vás výhodné.
Stejně jako biologická neuronová síť jsou rozpoznávány objekty různé složitosti. Jak se počet vrstev zvyšoval, všechno ztratilo kontakt s kůrou, protože v neuronové síti je omezený počet zón. 269 nebo mnoho, mnoho zón abstrakce, takže je zachován pouze nárůst složitosti, počtu prvků a receptivních polí.

Pokud se podíváme na příklad rozpoznávání obličeje, pak naše vnímavé pole první vrstvy bude malé, pak o něco větší, větší a tak dále, až nakonec rozpoznáme celý obličej.

Z hlediska toho, co je uvnitř našich filtrů, budou nejprve nakloněné tyčinky plus trocha barvy, poté části obličejů a poté budou rozpoznány celé obličeje každou buňkou vrstvy.
Jsou lidé, kteří tvrdí, že člověk vždy pozná lépe než síť. Je to tak?
V roce 2014 se vědci rozhodli otestovat, jak dobře rozpoznáváme ve srovnání s neuronovými sítěmi. Vzali 2 momentálně nejlepší sítě – AlexNet a síť Matthewa Zillera a Ferguse a porovnali je s odezvou různých oblastí mozku makaka, který se také naučil rozpoznávat některé objekty. Předměty byly ze světa zvířat, aby se opice nespletla, a prováděly se pokusy, aby se zjistilo, kdo lépe rozpozná.
Protože je nemožné získat jasnou odpověď od opice, byly do ní implantovány elektrody a reakce každého neuronu byla přímo měřena.
Ukázalo se, že za normálních podmínek reagovaly mozkové buňky stejně jako tehdejší nejmodernější model, tedy síť Matthewa Zillera.
Se zvýšením rychlosti zobrazování objektů a zvýšením množství šumu a objektů v obraze však výrazně klesá rychlost a kvalita rozpoznávání našeho mozku a mozku primátů. I ta nejjednodušší konvoluční neuronová síť dokáže lépe rozpoznat objekty. To znamená, že oficiálně neuronové sítě fungují lépe než náš mozek.
Klasické problémy konvolučních neuronových sítí
Vlastně jich není mnoho, patří do tří tříd. Patří mezi ně úlohy jako identifikace objektů, sémantická segmentace, rozpoznávání obličeje, rozpoznávání částí lidského těla, sémantická detekce hran, zvýraznění objektů pozornosti v obraze a zvýraznění povrchových normál. Lze je zhruba rozdělit do 3 úrovní: od úkolů nejnižší úrovně po úkoly nejvyšší úrovně.
Pomocí tohoto obrázku jako příkladu se podívejme, co jednotlivé úkoly dělají.
- Vymezení hranic- Jedná se o úlohu nejnižší úrovně, pro kterou se již klasicky používají konvoluční neuronové sítě.
- Určení vektoru k normále nám umožňuje rekonstruovat trojrozměrný obraz z dvourozměrného.
- Výraznost, identifikace objektů pozornosti- na to by člověk při pohledu na tento obrázek dával pozor.
- Sémantická segmentace umožňuje rozdělit objekty do tříd podle jejich struktury, aniž byste o těchto objektech cokoliv věděli, tedy ještě dříve, než jsou rozpoznány.
- Zvýraznění sémantických hranic- to je výběr hranic rozdělených do tříd.
- Zvýraznění částí lidského těla.
- A úkol nejvyšší úrovně je rozpoznávání samotných předmětů, kterou nyní zvážíme na příkladu rozpoznávání obličeje.
Rozpoznávání obličejů
První věc, kterou uděláme, je přejet detektorem obličeje přes snímek, abychom našli obličej. Poté obličej normalizujeme, vycentrujeme a spustíme pro zpracování v neuronové síti. Poté získáme sadu nebo vektor prvků, které jednoznačně popisuje rysy této tváře.
Poté můžeme tento příznakový vektor porovnat se všemi příznakovými vektory, které jsou uloženy v naší databázi, a získat tak referenci na konkrétní osobu, na její jméno, na její profil – vše, co můžeme do databáze uložit.
Přesně tak funguje náš produkt FindFace – je to bezplatná služba, která vám pomůže vyhledat profily lidí v databázi VKontakte.
Navíc máme API pro firmy, které chtějí naše produkty vyzkoušet. Poskytujeme služby pro detekci, ověření a identifikaci uživatelů.
Nyní jsme vyvinuli 2 scénáře. První je identifikace, hledání osoby v databázi. Druhým je ověření, jedná se o porovnání dvou obrázků s určitou pravděpodobností, že se jedná o stejnou osobu. Kromě toho v současné době vyvíjíme rozpoznávání emocí, rozpoznávání obrazu na videu a detekci živosti – to je pochopení toho, zda žije osoba před kamerou nebo fotografie.
Nějaká statistika. Při identifikaci při prohledávání 10 tisíc fotografií máme přesnost cca 95% v závislosti na kvalitě databáze a 99% přesnost ověření. A kromě toho je tento algoritmus velmi odolný vůči změnám - nemusíme se dívat do kamery, můžeme mít nějaké překážky: brýle, sluneční brýle, vousy, lékařskou masku. V některých případech můžeme dokonce překonat neuvěřitelné výzvy pro počítačové vidění, jako jsou brýle a maska.
Velmi rychlé vyhledávání, zpracování 1 miliardy fotografií trvá 0,5 sekundy. Vyvinuli jsme unikátní index rychlého vyhledávání. Můžeme pracovat i s nekvalitními snímky získanými z CCTV kamer. To vše dokážeme zpracovat v reálném čase. Fotografie můžete nahrávat přes webové rozhraní, přes Android, iOS a prohledávat 100 milionů uživatelů a jejich 250 milionů fotografií.
Jak jsem již řekl, obsadili jsme první místo v soutěži MegaFace - analog pro ImageNet, ale pro rozpoznávání obličeje. Funguje to už několik let, loni jsme byli nejlepší mezi 100 týmy z celého světa, včetně Googlu.
Rekurentní neuronové sítě
Rekurentní neuronové sítě používáme tehdy, když nám nestačí rozpoznat pouze obrázek. V případech, kdy je pro nás důležité zachovat konzistenci, potřebujeme pořadí toho, co se děje, používáme běžné rekurentní neuronové sítě.To se používá pro rozpoznávání přirozeného jazyka, zpracování videa, dokonce i pro rozpoznávání obrazu.
Nebudu mluvit o rozpoznávání přirozeného jazyka – po mé zprávě budou další dvě, které budou zaměřeny na rozpoznávání přirozeného jazyka. Proto budu mluvit o práci rekurentních sítí na příkladu rozpoznávání emocí.
Co jsou rekurentní neuronové sítě? To je přibližně stejné jako běžné neuronové sítě, ale se zpětnou vazbou. Pro přenos předchozího stavu systému na vstup neuronové sítě nebo do některé z jejích vrstev potřebujeme zpětnou vazbu.
Řekněme, že zpracováváme emoce. I v úsměvu – jedné z nejjednodušších emocí – je několik momentů: od neutrálního výrazu obličeje až po okamžik, kdy máme plný úsměv. Následují za sebou sekvenčně. Abychom tomu dobře porozuměli, musíme být schopni pozorovat, jak se to děje, a přenést to, co bylo na předchozím snímku, do dalšího kroku systému.

V roce 2005 na soutěži Emotion Recognition in the Wild představil tým z Montrealu rekurentní systém speciálně pro rozpoznávání emocí, který vypadal velmi jednoduše. Měl jen pár konvolučních vrstev a pracoval výhradně s videem. Letos přidali také rozpoznávání zvuku a agregovaná data po snímku získaná z konvolučních neuronových sítí, data audio signálu s provozem rekurentní neuronové sítě (s návratem stavu) a v soutěži obsadili první místo.
Posílení učení
Dalším typem neuronových sítí, který se v poslední době používá velmi často, ale nedostává se mu takové publicity jako předchozí 2 typy, je učení s hlubokým posilováním.Faktem je, že v předchozích dvou případech používáme databáze. Buď máme data z tváří, nebo data z obrázků, nebo data s emocemi z videí. Pokud to nemáme, pokud to nemůžeme natočit, jak můžeme naučit robota sbírat předměty? Děláme to automaticky – nevíme, jak to funguje. Jiný příklad: kompilace velkých databází v počítačových hrách je obtížná a není to nutné, lze to udělat mnohem jednodušeji.
Každý pravděpodobně slyšel o úspěchu učení hlubokého posílení v Atari a Go.
Kdo slyšel o Atari? Někdo to slyšel, dobře. Myslím, že každý slyšel o AlphaGo, takže vám ani neřeknu, co se tam přesně děje.

Co se děje v Atari? Architektura této neuronové sítě je zobrazena vlevo. Učí se hraním sama se sebou, aby získala maximální odměnu. Maximální odměna je nejrychlejší možný výsledek hry s nejvyšším možným skóre.
Vpravo nahoře je poslední vrstva neuronové sítě, která znázorňuje celý počet stavů systému, který proti sobě hrál pouhé dvě hodiny. Žádoucí výsledky hry s maximální odměnou jsou zobrazeny červeně a nežádoucí jsou zobrazeny modře. Síť si buduje určité pole a přes své natrénované vrstvy se posouvá do stavu, kterého chce dosáhnout.
V robotice je situace trochu jiná. Proč? Zde narážíme na několik potíží. Za prvé, nemáme mnoho databází. Zadruhé potřebujeme koordinovat tři systémy najednou: vnímání robota, jeho akce pomocí manipulátorů a jeho paměť – co bylo provedeno v předchozím kroku a jak to bylo provedeno. Obecně je to všechno velmi obtížné.
Faktem je, že ani jedna neuronová síť, dokonce ani hluboké učení v tuto chvíli, se s tímto úkolem nedokáže dostatečně efektivně vypořádat, takže hluboké učení je pouze část toho, co roboti potřebují. Například Sergej Levin nedávno poskytl systém, který učí robota chytat předměty.

Zde jsou experimenty, které provedl na svých 14 robotických pažích.
Co se tam děje? V těchto mísách, které vidíte před sebou, jsou různé předměty: pera, gumy, menší a větší hrnky, hadry, různé textury, různé tvrdosti. Není jasné, jak naučit robota je zachytit. Po mnoho hodin a dokonce i týdnů se roboti trénovali, aby byli schopni tyto předměty uchopit, a byly o tom sestavovány databáze.
Databáze jsou jakousi reakcí prostředí, kterou potřebujeme nashromáždit, abychom mohli robota v budoucnu vycvičit, aby něco dělal. V budoucnu se roboti budou učit z této sady stavů systému.
Nestandardní aplikace neuronových sítí
Bohužel je to konec, nemám moc času. Povím vám o těch nestandardních řešeních, která v současnosti existují a která podle mnoha předpovědí budou mít v budoucnu nějaké uplatnění.Vědci ze Stanfordu nedávno přišli s velmi neobvyklou aplikací neuronové sítě CNN k předpovídání chudoby. Co dělali?
Koncept je ve skutečnosti velmi jednoduchý. Faktem je, že v Africe míra chudoby přesahuje všechny představitelné a nepředstavitelné meze. Nemají ani možnost sbírat sociálně demografická data. Od roku 2005 proto nemáme vůbec žádná data o tom, co se tam děje.
Vědci shromáždili denní a noční mapy ze satelitů a po určitou dobu je přivedli do neuronové sítě.
Neuronová síť byla předkonfigurována na ImageNet. To znamená, že první vrstvy filtrů byly nakonfigurovány tak, aby dokázala rozpoznat některé velmi jednoduché věci, například střechy domů, pro vyhledávání sídel na denních mapách. Poté byly denní mapy v porovnání s nočními mapami osvětlení stejné plochy povrchu, aby bylo řečeno, kolik peněz má obyvatelstvo na osvětlení svých domů v noci.

Zde vidíte výsledky předpovědi sestavené neuronovou sítí. Předpověď byla vytvořena v různých rozlišeních. A vidíte – úplně poslední snímek – skutečná data shromážděná ugandskou vládou v roce 2005.
Vidíte, že neuronová síť udělala poměrně přesnou předpověď, a to i s mírným posunem od roku 2005.
Samozřejmě byly vedlejší účinky. Vědci, kteří se zabývají hlubokým učením, jsou vždy překvapeni, když objeví různé vedlejší účinky. Například jako to, že se síť naučila rozpoznávat vodu, lesy, velká staveniště, silnice – to vše bez učitelů, bez předem vytvořených databází. Obecně zcela nezávisle. Byly tam určité vrstvy, které reagovaly například na silnice.
A poslední aplikací, o které bych chtěl mluvit, je sémantická segmentace 3D obrazů v medicíně. Obecně platí, že lékařské zobrazování je komplexní obor, se kterým je velmi obtížné pracovat.
Důvodů je několik.
- Máme velmi málo databází. Najít obrázek mozku, ba co víc, poškozeného, není tak snadné a také ho není možné odkudkoli vzít.
- I když máme takový obrázek, musíme vzít medika a donutit ho ručně umístit všechny vícevrstvé obrázky, což je časově velmi náročné a extrémně neefektivní. Ne všichni lékaři na to mají prostředky.
- Vyžaduje se velmi vysoká přesnost. Lékařský systém nemůže dělat chyby. Při rozpoznávání se například kočky nerozpoznaly - žádný velký problém. A pokud jsme nádor nerozpoznali, tak to už není moc dobré. Požadavky na spolehlivost systému jsou zde obzvláště přísné.
- Obrázky jsou v trojrozměrných prvcích - voxely, nikoli pixely, což přináší vývojářům systému další složitost.
Kde se používá: identifikace poškození po nárazu, hledání nádoru v mozku, v kardiologii k určení, jak funguje srdce.

Zde je příklad pro stanovení objemu placenty.
Automaticky to funguje dobře, ale ne dost dobře na to, aby to bylo uvolněno do výroby, takže to teprve začíná. Existuje několik startupů, které vytvářejí takové systémy lékařského vidění. Obecně platí, že v blízké budoucnosti bude v hlubokém učení spousta startupů. Říkají, že investoři rizikového kapitálu vyčlenili za posledních šest měsíců více rozpočtu na startupy s hlubokým učením než za posledních 5 let.
Tato oblast se aktivně rozvíjí, existuje mnoho zajímavých směrů. Žijeme v zajímavé době. Pokud jste zapojeni do hlubokého učení, pak je pravděpodobně čas, abyste otevřeli svůj vlastní startup.
No asi to tady zabalím. Děkuji mnohokrát.
Správná formulace otázky by měla znít: jak trénovat vlastní neuronovou síť? Síť nemusíte psát sami; musíte vzít jednu z hotových implementací, kterých je mnoho; předchozí autoři poskytli odkazy. Ale tato implementace sama o sobě je podobná počítači, do kterého nebyly staženy žádné programy. Aby síť vyřešila váš problém, je potřeba ji naučit.
A tady přichází to nejdůležitější, co k tomu potřebujete: DATA. Existuje mnoho příkladů problémů, které budou přiváděny na vstup neuronové sítě, a správných odpovědí na tyto problémy. Neuronová síť se z toho naučí samostatně dávat tyto správné odpovědi.
A tady vzniká spousta detailů a nuancí, které musíte znát a pochopit, aby to vše mělo šanci dát přijatelný výsledek. Není možné je zde všechny pokrýt, proto uvedu jen některé body. Za prvé, objem dat. To je velmi důležitý bod. Velké společnosti, jejichž činnost souvisí se strojovým učením, mají obvykle speciální oddělení a zaměstnance věnující se pouze sběru a zpracování dat pro trénování neuronových sítí. Často je nutné nakupovat data a veškerá tato činnost má za následek významnou nákladovou položku. Za druhé, prezentace dat. Pokud je každý objekt ve vašem problému reprezentován relativně malým počtem číselných parametrů, pak existuje šance, že je lze zadat přímo do neuronové sítě v takto hrubé podobě a získat přijatelný výstupní výsledek. Ale pokud jsou objekty složité (obrázky, zvuk, objekty proměnných rozměrů), pak s největší pravděpodobností budete muset vynaložit čas a úsilí na to, abyste z nich extrahovali smysluplné vlastnosti pro řešený problém. To samo o sobě může zabrat spoustu času a mít mnohem větší dopad na konečný výsledek než dokonce typ a architektura neuronové sítě zvolené pro použití.
Často se vyskytují případy, kdy se skutečná data ukáží jako příliš hrubá a nevhodná pro použití bez předběžného zpracování: obsahují opomenutí, šum, nesrovnalosti a chyby.
Data by také měla být shromažďována nejen tak, ale kompetentně a promyšleně. V opačném případě se natrénovaná síť může chovat podivně a dokonce vyřešit úplně jiný problém, než autor zamýšlel.
Musíte si také představit, jak správně zorganizovat proces učení, aby se síť nepřetrénovala. Složitost sítě je nutné volit na základě rozměru dat a jejich množství. Některá data by měla být ponechána stranou pro testování a neměla by být použita během školení, aby bylo možné posoudit skutečnou kvalitu práce. Někdy je třeba různým objektům v tréninkové sadě přiřadit různé váhy. Někdy je užitečné tyto váhy během procesu učení měnit. Někdy je užitečné začít trénovat na části dat a zbývající data přidávat v průběhu trénování. Obecně se to dá přirovnat k vaření: každá hospodyňka má své vlastní techniky, jak připravit i stejná jídla.
Tento článek obsahuje materiály – převážně v ruštině – pro základní studium umělých neuronových sítí.
Umělá neuronová síť neboli ANN je matematický model, stejně jako jeho softwarové nebo hardwarové ztělesnění, postavený na principu organizace a fungování biologických neuronových sítí - sítí nervových buněk živého organismu. Věda o neuronových sítích existuje již poměrně dlouho, ale právě v souvislosti s nejnovějšími výdobytky vědeckého a technologického pokroku si tato oblast začíná získávat na popularitě.
knihy
Výběr začněme klasickým způsobem studia – prostřednictvím knih. Vybrali jsme ruskojazyčné knihy s velkým množstvím příkladů:
- F. Wasserman, Neuropočítačová technika: Teorie a praxe. 1992
Kniha uvádí veřejně přístupnou formou základy stavby neuropočítačů. Je popsána struktura neuronových sítí a různé algoritmy pro jejich konfiguraci. Samostatné kapitoly jsou věnovány implementaci neuronových sítí. - S. Khaikin, Neuronové sítě: Kompletní kurz. 2006
Jsou zde diskutována hlavní paradigmata umělých neuronových sítí. Předkládaný materiál obsahuje striktní matematické zdůvodnění všech paradigmat neuronových sítí, je ilustrován příklady, popisy počítačových experimentů, obsahuje mnoho praktických problémů a také rozsáhlou bibliografii.
D. Forsythe, Počítačové vidění. Moderní přístup. 2004
Počítačové vidění je v této fázi vývoje globálních digitálních počítačových technologií jednou z nejoblíbenějších oblastí. Je vyžadován ve výrobě, řízení robotů, automatizaci procesů, lékařských a vojenských aplikacích, satelitním sledování a aplikacích osobních počítačů, jako je získávání digitálního obrazu.
Video
Není nic přístupnějšího a srozumitelnějšího než vizuální učení pomocí videa:
- Chcete-li pochopit, co je strojové učení obecně, podívejte se sem tyto dvě přednášky od Yandex ShAD.
- Úvod do základních principů návrhu neuronových sítí – skvělé pro pokračování vašeho úvodu do neuronových sítí.
- Přednáškový kurz na téma „Počítačové vidění“ z Moskevské státní univerzity Computing Machinery. Počítačové vidění je teorie a technologie vytváření umělých systémů, které detekují a klasifikují objekty v obrazech a videích. Tyto přednášky lze považovat za úvod do této zajímavé a složité vědy.
Vzdělávací zdroje a užitečné odkazy
- Portál umělé inteligence.
- Laboratoř „Jsem inteligence“.
- Neuronové sítě v Matlabu.
- Neuronové sítě v Pythonu (anglicky):
- Klasifikace textu pomocí ;
- Jednoduché .
- Neuronová síť zapnutá.
Série našich publikací na toto téma
Již dříve jsme zveřejnili kurz #neuralnetwork@tproger na neuronových sítích. V tomto seznamu jsou publikace uspořádány v pořadí studia pro vaše pohodlí.
Mnoho termínů v neuronových sítích souvisí s biologií, takže začněme od začátku:
Mozek je složitá věc, ale lze ji rozdělit do několika hlavních částí a operací:

Původcem může být vnitřní(například obrázek nebo nápad):

Nyní se podíváme na základní a zjednodušené díly mozek:

Mozek je obecně jako kabelová síť.
Neuron- základní výpočetní jednotka v mozku, přijímá a zpracovává chemické signály z jiných neuronů a v závislosti na řadě faktorů buď nedělá nic, nebo generuje elektrický impuls, neboli akční potenciál, který pak vysílá signály přes synapse do sousedních jedničky příbuzný neurony:

Sny, vzpomínky, samoregulační pohyby, reflexy a obecně vše, co si myslíte nebo děláte - vše se děje díky tomuto procesu: miliony, nebo dokonce miliardy neuronů pracují na různých úrovních a vytvářejí spojení, která vytvářejí různé paralelní subsystémy a představují biologický neuron síť.
Samozřejmě jsou to všechno zjednodušení a zobecnění, ale díky nim můžeme popsat jednoduché
nervová síť:

A popište to formálně pomocí grafu:

Zde je zapotřebí určité upřesnění. Kruhy jsou neurony a čáry jsou spojení mezi nimi,
a aby byly věci v tomto bodě jednoduché, vztahy představují přímý pohyb informací zleva doprava. První neuron je aktuálně aktivní a je zvýrazněn šedou barvou. Také jsme mu přiřadili číslo (1, pokud to funguje, 0, pokud ne). Čísla mezi neurony ukazují hmotnost komunikace.
Výše uvedené grafy znázorňují časový okamžik sítě, pro přesnější zobrazení jej musíte rozdělit do časových úseků:

Chcete-li vytvořit svou vlastní neuronovou síť, musíte pochopit, jak váhy ovlivňují neurony a jak se neurony učí. Jako příklad si vezměme králíka (testovacího králíka) a uveďme jej do podmínek klasického pokusu.

Když je na ně nasměrován bezpečný proud vzduchu, králíci, stejně jako lidé, blikají:

Tento model chování lze znázornit v grafech:

Stejně jako v předchozím diagramu tyto grafy zobrazují pouze okamžik, kdy králík cítí dech a my tedy zakódovat whiff jako booleovská hodnota. Navíc na základě hodnoty hmotnosti vypočítáme, zda druhý neuron vystřelí. Pokud je rovna 1, pak senzorický neuron vystřelí, mrkneme; je-li váha menší než 1, nemrkáme: druhý neuron omezit- 1.
Představme si ještě jeden prvek – bezpečný zvukový signál:

Zájem králíka můžeme modelovat takto:

Hlavní rozdíl je v tom, že nyní je hmotnost rovna nula, takže jsme nedostali blikajícího králíka, tedy alespoň zatím ne. Nyní naučme králíčka mrkat na povel mícháním
Stimuly (pípnutí a foukání):

Je důležité, aby k těmto událostem docházelo v různých časech éra, v grafech to bude vypadat takto:

Zvuk sám o sobě nic nedělá, ale proudění vzduchu stále způsobuje, že králík mrká, a to ukazujeme prostřednictvím vah násobených podněty (červeně).
Vzdělání komplexní chování lze zjednodušeně vyjádřit jako postupnou změnu hmotnosti mezi připojenými neurony v průběhu času.
Pro výcvik králíka opakujeme kroky:

Pro první tři pokusy budou schémata vypadat takto:

Upozorňujeme, že váha pro zvukový podnět se zvyšuje po každém opakování (zvýrazněno červeně), tato hodnota je aktuálně libovolná - zvolili jsme 0,30, ale číslo může být jakékoli, i záporné. Po třetím opakování už změnu v chování králíka nezaznamenáte, ale po čtvrtém opakování se stane něco úžasného - chování se změní.

Odstranili jsme expozici vzduchu, ale králík stále mrká, když slyší pípnutí! Náš poslední diagram může vysvětlit toto chování:

Vycvičili jsme králíka, aby reagoval na zvuk mrkáním.

Ve skutečném experimentu tohoto druhu může k dosažení výsledku trvat více než 60 opakování.
Nyní opustíme biologický svět mozku a králíků a pokusíme se tomu vše přizpůsobit
naučili vytvářet umělou neuronovou síť. Nejprve zkusme udělat jednoduchý úkol.
Řekněme, že máme stroj se čtyřmi tlačítky, který vydává jídlo, když se stiskne to správné
tlačítka (dobře, nebo energie, pokud jste robot). Úkolem je zjistit, které tlačítko dává odměnu:

Co dělá tlačítko po kliknutí, můžeme znázornit (schematicky) takto:

Nejlepší je tento problém vyřešit úplně, takže se podívejme na všechny možné výsledky, včetně toho správného:

Kliknutím na 3. tlačítko dostanete večeři.
Abychom reprodukovali neuronovou síť v kódu, musíme nejprve vytvořit model nebo graf, se kterým lze síť porovnat. Zde je jeden graf vhodný pro daný úkol, navíc dobře zobrazuje svou biologickou analogii:

Tato neuronová síť jednoduše přijímá příchozí informace – v tomto případě by to bylo vnímání toho, které tlačítko bylo stisknuto. Dále síť nahradí příchozí informace váhami a provede závěry založené na přidání vrstvy. Zní to trochu zmateně, ale podívejme se, jak je tlačítko reprezentováno v našem modelu:

Všimněte si, že všechny váhy jsou 0, takže neuronová síť je jako dítě, zcela prázdná, ale zcela propojená.
Vnější událost tedy spárujeme se vstupní vrstvou neuronové sítě a vypočítáme hodnotu na jejím výstupu. Může, ale nemusí se shodovat s realitou, ale my to prozatím ignorujeme a začneme popisovat problém způsobem, kterému počítač rozumí. Začněme zadáním vah (použijeme JavaScript):
Vstupy var = ; var váhy = ; // Pro usnadnění lze tyto vektory volat
Dalším krokem je vytvoření funkce, která vezme vstupní hodnoty a váhy a vypočítá výstupní hodnotu:
Funkce vyhodnotitNeuralNetwork(inputVector, weightVector)( var result = 0; inputVector.forEach(function(inputValue,weightIndex) (layerValue = inputValue*weightVector; result += layerValue; )); return (result.toFixed(2)); ) / / Může se zdát složité, ale vše, co dělá, je spárování párů hmotnost/vstup a sečtení výsledku
Jak se dalo očekávat, pokud spustíme tento kód, dostaneme stejný výsledek jako v našem modelu nebo grafu...
EvaluateNeuralNetwork(vstupy, váhy); // 0,00
Živý příklad: Neural Net 001.
Dalším krokem ke zlepšení naší neuronové sítě bude způsob, jak si ověřit vlastní výstup nebo výsledné hodnoty způsobem srovnatelným s reálnou situací,
nejprve zakódujme tuto konkrétní realitu do proměnné:

Abychom odhalili nesrovnalosti (a kolik jich je), přidáme chybovou funkci:
Chyba = realita – výstup neuronové sítě
Pomocí něj můžeme vyhodnotit výkon naší neuronové sítě:

Ale co je důležitější, co situace, kdy realita přináší pozitivní výsledek?

Nyní víme, že náš model neuronové sítě je rozbitý (a víme jak moc), skvělé! Skvělé je, že nyní můžeme pomocí chybové funkce ovládat naše učení. Ale to vše bude dávat smysl, pokud předefinujeme chybovou funkci takto:
Chyba = Požadovaný výstup- Výstup neuronové sítě
Nepolapitelný, ale tak důležitý rozpor, který tiše ukazuje, že ano
použít předchozí výsledky k porovnání s budoucími akcemi
(a pro naučení, jak uvidíme později). To existuje i v reálném životě, plném
opakující se vzorce, takže se může stát evoluční strategií (dobře, v
většina případů).
Vstup var = ; var váhy = ; var požadovanýVýsledek = 1;
A nová funkce:
Funkce vyhodnotitNeuralNetError(desired,actual) ( return (desired - current); ) // Po vyhodnocení sítě i chyby bychom dostali: // "Výstup neurální sítě: 0.00 Error: 1"
Živý příklad: Neural Net 002.
Pojďme si to shrnout. Začali jsme s problémem, udělali jsme jeho jednoduchý model v podobě biologické neuronové sítě a měli způsob, jak změřit jeho výkon v porovnání s realitou nebo požadovaný výsledek. Nyní musíme najít způsob, jak tuto nesrovnalost napravit, proces, který lze pro počítače i lidi považovat za učení.
Jak trénovat neuronovou síť?
Základem tréninku pro biologické i umělé neuronové sítě je opakování
A algoritmy učení, takže s nimi budeme pracovat samostatně. Začněme s
tréninkové algoritmy.
V přírodě se algoritmy učení týkají fyzikálních nebo chemických změn
vlastnosti neuronů po experimentech:

Dramatická ilustrace toho, jak se dva neurony v průběhu času mění v kódu a našem modelu „učícího se algoritmu“ znamená, že v průběhu času jednoduše změníme věci, abychom si usnadnili život. Přidejme tedy proměnnou, která ukáže, jak snadný je život:
Var learningRate = 0,20; // Čím větší hodnota, tím rychlejší bude proces učení :)
A co se tím změní?
Tím se změní hmotnosti (stejně jako králík!), zejména výstupní hmotnost, kterou chceme vyrobit:

Jak nakódovat takový algoritmus je vaše volba, pro jednoduchost přidávám k váze faktor učení, zde je ve formě funkce:
Funkce learn(inputVector, weightVector) ( weightVector.forEach(function(weight, index, weights) ( if (inputVector > 0) (weights = weight + learningRate; ) )); )
Při použití tato tréninková funkce jednoduše přidá náš faktor učení k vektoru hmotnosti aktivní neuron, před a po kole tréninku (nebo opakování) budou výsledky následující:
// Původní vektor hmotnosti: // Neural Net output: 0.00 Error: 1 learn(input, weights); // Nový vektor hmotnosti: // Neural Net output: 0.20 Error: 0.8 // Pokud to není zřejmé, výstup neuronové sítě se blíží 1 (kuřecí výstup) – což je to, co jsme chtěli, takže můžeme dojít k závěru, že se pohybujeme směrem správným směrem
Živý příklad: Neural Net 003.
Dobře, teď, když jdeme správným směrem, bude posledním kouskem této skládačky implementace opakování.
Není to tak složité, v přírodě prostě děláme to samé znovu a znovu, ale v kódu jen určíme počet opakování:
Var pokusy = 6;
A implementace funkce počtu opakování do naší tréninkové neuronové sítě bude vypadat takto:
Funkční sled (pokusy) ( pro (i = 0; i< trials; i++) {
neuralNetResult = evaluateNeuralNetwork(input, weights);
learn(input, weights);
}
}
No, tady je naše závěrečná zpráva:
Neural Net output: 0,00 Chyba: 1,00 Váhový vektor: Neural Čistý výstup: 0,20 Chyba: 0,80 Váhový vektor: Neural Net output: 0,40 Chyba: 0,60 Váhový vektor: Neural Čistý výstup: 0,60 Chyba: 0,40 Váhový vektor: Neural Čistý výstup: 0,8 : 0,20 Váhový vektor: Neural Čistý výstup: 1,00 Chyba: 0,00 Váhový vektor: // Kuřecí večeře !
Živý příklad: Neural Net 004.
Nyní máme hmotnostní vektor, který vytvoří pouze jeden výstup (kuře k večeři), pokud vstupní vektor odpovídá skutečnosti (kliknutí na třetí tlačítko).
Takže co je nejlepší věc, kterou jsme právě udělali?
V tomto konkrétním případě naše neuronová síť (po natrénování) dokáže rozpoznat vstupní data a říci, co povede k požadovanému výsledku (ještě budeme muset naprogramovat konkrétní situace):

Navíc je to škálovatelný model, hračka a nástroj pro naše učení. Mohli jsme se dozvědět něco nového o strojovém učení, neuronových sítích a umělé inteligenci.
Upozornění pro uživatele:
- Neexistuje žádný mechanismus pro ukládání naučených vah, takže tato neuronová síť zapomene vše, co zná. Při aktualizaci nebo opětovném spuštění kódu potřebujete alespoň šest úspěšných iterací, aby se síť plně naučila, pokud si myslíte, že člověk nebo stroj bude mačkat tlačítka náhodně... To bude nějakou dobu trvat.
- Biologické sítě pro učení důležitých věcí mají rychlost učení 1, takže by byla potřeba pouze jedna úspěšná iterace.
- Existuje algoritmus učení, který se velmi podobá biologickým neuronům a má chytlavý název: Widroff-hoffovo pravidlo nebo Widroff-hoff školení.
- Neuronální prahy (v našem příkladu 1) a efekty rekvalifikace (při velkém počtu opakování bude výsledek větší než 1) se neberou v úvahu, ale jsou ve své podstatě velmi důležité a jsou zodpovědné za velké a složité bloky behaviorálních reakcí. . Stejně tak záporné váhy.
Poznámky a seznam odkazů pro další čtení
Snažil jsem se vyhnout matematice a striktním termínům, ale pokud vás to zajímá, postavili jsme perceptron, který je definován jako supervizovaný algoritmus učení (učení pod dohledem) duálních klasifikátorů - těžkých věcí.Biologická struktura mozku není jednoduché téma, částečně kvůli nepřesnosti a částečně kvůli jeho složitosti. Je lepší začít s Neuroscience (Purves) a Cognitive Neuroscience (Gazzaniga). Upravil jsem a upravil příklad králíka z Gateway to Memory (Gluck), což je také skvělý úvod do světa grafů.
Úvod do neuronových sítí (Gurney) je dalším skvělým zdrojem pro všechny vaše potřeby AI.
A nyní v Pythonu! Děkujeme Ilya Andshmidtovi za poskytnutí verze Pythonu:
Vstupy = váhy = požadovaný_výsledek = 1 rychlost učení = 0,2 pokusů = 6 def vyhodnotit_neurální_síť(vstupní_pole, pole vah): výsledek = 0 pro i v rozsahu(len(vstupní_pole)): hodnota_vrstvy = pole_vstupu[i] * pole vah[i] výsledek += hodnota_vrstvy print("evaluate_neural_network: " + str(výsledek)) print("váhy: " + str(váhy)) return result def vyhodnotit_chybu(požadovaná, skutečná): chyba = požadovaná - aktuální tisk("chyba_vyhodnocení: " + str(chyba) ) return error def learn(input_array, weight_array): print("learning...") for i in range(len(input_array)): if input_array[i] > 0: weight_array[i] += learning_rate def train(trials ): pro i v rozsahu (zkoušky): neural_net_result = vyhodnotit_neurální_síť (vstupy, váhy) učit se (vstupy, váhy) trénovat (zkoušky)
A teď GO! Za tuto verzi děkuji Kieran Maher.
Hlavní import balíčku ("fmt" "math") func main() ( fmt.Println("Vytváření vstupů a vah ...") inputs:= float64(0,00, 0,00, 1,00, 0,00) weights:= float64(0,00, 0,00, 0,00, 0,00) požadované:= 1,00 rychlost učení:= 0,20 pokusy:= 6 vlak (pokusy, vstupy, váhy, požadované, rychlost učení) ) func train (pokusy int, vstupy float64, váhy float64, požadované float64, learningRate float64) ( pro i:= 1;i< trials; i++ { weights = learn(inputs, weights, learningRate) output:= evaluate(inputs, weights) errorResult:= evaluateError(desired, output) fmt.Print("Output: ") fmt.Print(math.Round(output*100) / 100) fmt.Print("\nError: ") fmt.Print(math.Round(errorResult*100) / 100) fmt.Print("\n\n") } } func learn(inputVector float64, weightVector float64, learningRate float64) float64 { for index, inputValue:= range inputVector { if inputValue >0,00 ( weightVector = weightVector + learningRate ) return weightVector ) func vyhodnotit (inputVector float64, weightVector float64) float64 ( result:= 0,00 pro index, inputValue:= rozsah inputVector ( layerValue:= inputValue * weightVector result = výsledek +) weightVector výsledek = výsledek func vyhodnotitError (požadovaný float64, skutečný float64) float64 ( požadovaný návrat - skutečný )
Můžete pomoci a převést nějaké prostředky na rozvoj webu
V souladu s tím neuronová síť přijímá dvě čísla jako vstup a musí vydávat další číslo - odpověď. Nyní o samotných neuronových sítích.
Co je to neuronová síť?
Neuronová síť je posloupnost neuronů spojených synapsemi. Struktura neuronové sítě přišla do světa programování přímo z biologie. Díky této struktuře získává stroj schopnost analyzovat a dokonce si pamatovat různé informace. Neuronové sítě jsou také schopny příchozí informace nejen analyzovat, ale také je reprodukovat ze své paměti. Pro zájemce se určitě podívejte na 2 videa z TED Talks: Video 1 , Video 2). Jinými slovy, neuronová síť je strojová interpretace lidského mozku, která obsahuje miliony neuronů přenášejících informace ve formě elektrických impulsů.
Jaké typy neuronových sítí existují?
Prozatím budeme uvažovat příklady na nejzákladnějším typu neuronových sítí – dopředné síti (dále jen dopředná síť). Také v následujících článcích představím více konceptů a řeknu vám o rekurentních neuronových sítích. SPR, jak už z názvu vyplývá, je síť se sekvenčním propojením neuronových vrstev, ve které informace proudí vždy pouze jedním směrem.
K čemu jsou neuronové sítě?
Neuronové sítě se používají k řešení složitých problémů, které vyžadují analytické výpočty podobné těm, které dělá lidský mozek. Nejběžnější aplikace neuronových sítí jsou:
Klasifikace- rozdělení dat podle parametrů. Například dostanete jako vstup soubor lidí a musíte se rozhodnout, kterým z nich připíšete uznání a kterým ne. Tuto práci může provádět neuronová síť, která analyzuje informace, jako je věk, solventnost, úvěrová historie atd.
Předpověď- schopnost předvídat další krok. Například vzestup nebo pokles akcií na základě situace na akciovém trhu.
Uznání- V současné době nejrozšířenější využití neuronových sítí. Používá se v Googlu, když hledáte fotku nebo ve fotoaparátech telefonu, když detekuje polohu vašeho obličeje a zvýrazní ji a mnoho dalšího.
Abychom nyní pochopili, jak neuronové sítě fungují, pojďme se podívat na jejich součásti a jejich parametry.
Co je to neuron?
Neuron je výpočetní jednotka, která přijímá informace, provádí na nich jednoduché výpočty a přenáší je dále. Dělí se na tři hlavní typy: vstup (modrý), skrytý (červený) a výstup (zelený). Existuje také posunový neuron a kontextový neuron, o kterých si povíme v příštím článku. V případě, kdy se neuronová síť skládá z velkého počtu neuronů, zavádí se pojem vrstva. V souladu s tím existuje vstupní vrstva, která přijímá informace, n skrytých vrstev (obvykle ne více než 3), které je zpracovávají, a výstupní vrstva, která vydává výsledek. Každý neuron má 2 hlavní parametry: vstupní data a výstupní data. V případě vstupního neuronu: input=output. Ve zbytku vstupní pole obsahuje celkové informace všech neuronů z předchozí vrstvy, poté je normalizováno pomocí aktivační funkce (prozatím si to představme jako f(x)) a končí ve výstupním poli.

Důležité si pamatovatže neurony operují s čísly v rozsahu nebo [-1,1]. Ale jak, ptáte se, pak zpracovat čísla, která spadají mimo tento rozsah? V tuto chvíli je nejjednodušší odpovědí vydělit 1 tímto číslem. Tento proces se nazývá normalizace a velmi často se používá v neuronových sítích. Více o tom trochu později.
Co je synapse?

Synapse je spojení mezi dvěma neurony. Synapse mají 1 parametr – váhu. Díky němu se vstupní informace mění při přenosu z jednoho neuronu na druhý. Řekněme, že existují 3 neurony, které přenášejí informace na další. Pak máme 3 váhy odpovídající každému z těchto neuronů. U neuronu, jehož hmotnost je větší, bude tato informace dominantní v dalším neuronu (například míchání barev). Ve skutečnosti je sada vah neuronové sítě nebo matice vah jakýmsi mozkem celého systému. Právě díky těmto vahám jsou vstupní informace zpracovány a převedeny do výsledku.
Důležité si pamatovat, že při inicializaci neuronové sítě jsou váhy umístěny v náhodném pořadí.
Jak funguje neuronová síť?

Tento příklad ukazuje část neuronové sítě, kde písmena I označují vstupní neurony, písmeno H značí skrytý neuron a písmeno w značí váhy. Vzorec ukazuje, že vstupní informace je součtem všech vstupních dat vynásobených jejich odpovídajícími váhami. Potom dáme jako vstup 1 a 0. Nechť w1=0,4 a w2 = 0,7 Vstupní data neuronu H1 budou následující: 1*0,4+0*0,7=0,4. Nyní, když máme vstup, můžeme získat výstup zapojením vstupu do aktivační funkce (o tom později). Nyní, když máme výstup, předáme ho dál. A tak opakujeme pro všechny vrstvy, dokud nedosáhneme výstupního neuronu. Po prvním spuštění takové sítě uvidíme, že odpověď není zdaleka správná, protože síť není natrénována. Pro zlepšení výsledků ji budeme trénovat. Než se ale naučíme, jak na to, představíme si pár pojmů a vlastností neuronové sítě.
Aktivační funkce
Aktivační funkce je způsob normalizace vstupních dat (o tom jsme hovořili dříve). To znamená, že pokud máte na vstupu velké číslo a projdete ho aktivační funkcí, získáte výstup v rozsahu, který potřebujete. Aktivačních funkcí je poměrně hodně, takže uvážíme ty nejzákladnější: Lineární, Sigmoidní (Logistická) a Hyperbolická tečna. Jejich hlavním rozdílem je rozsah hodnot.
Lineární funkce
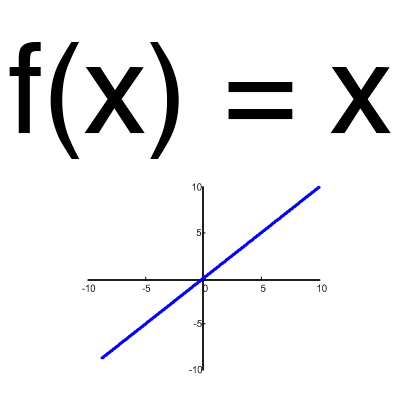
Tato funkce se téměř nepoužívá, kromě případů, kdy potřebujete otestovat neuronovou síť nebo předat hodnotu bez konverze.
Sigmoid

Toto je nejběžnější aktivační funkce a její rozsah hodnot je . Zde je zobrazena většina příkladů na webu a někdy se tomu také říká logistická funkce. Pokud tedy ve vašem případě existují záporné hodnoty (například akcie mohou jít nejen nahoru, ale i dolů), budete potřebovat funkci, která také zachytí záporné hodnoty.
Hyperbolická tečna

Hyperbolickou tečnu má smysl používat pouze tehdy, když vaše hodnoty mohou být záporné i kladné, protože rozsah funkce je [-1,1]. Tuto funkci není vhodné používat pouze s kladnými hodnotami, protože to výrazně zhorší výsledky vaší neuronové sítě.
Tréninkový set
Tréninková sada je posloupnost dat, se kterými pracuje neuronová síť. V našem případě eliminace nebo (xor) máme pouze 4 různé výsledky, to znamená, že budeme mít 4 tréninkové sady: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Opakování
Jedná se o jakési počítadlo, které se zvyšuje pokaždé, když neuronová síť projde jednou tréninkovou sadou. Jinými slovy, toto je celkový počet tréninkových sad dokončených neuronovou sítí.
éra
Při inicializaci neuronové sítě je tato hodnota nastavena na 0 a má ručně nastavený strop. Čím větší epocha, tím lépe trénovaná síť a podle toho i její výsledek. Epocha se zvyšuje pokaždé, když projdeme celou sadu tréninkových sad, v našem případě 4 sady nebo 4 iterace.

Důležité nepleťte si iteraci s epochou a pochopte posloupnost jejich přírůstku. První n
jednou se zvýší iterace a pak epocha a ne naopak. Jinými slovy, nemůžete nejprve trénovat neuronovou síť pouze na jedné sadě, pak na další a tak dále. Každou sadu musíte trénovat jednou za éru. Tímto způsobem se můžete vyhnout chybám ve výpočtech.
Chyba
Chyba je procento, které odráží rozdíl mezi očekávanými a přijatými odpověďmi. Chyba se tvoří každou éru a musí klesat. Pokud se tak nestane, pak děláte něco špatně. Chybu lze vypočítat různými způsoby, ale my budeme uvažovat pouze tři hlavní metody: Střední kvadratická chyba (dále jen MSE), Root MSE a Arctan. Neexistuje žádné omezení použití, jako je tomu u aktivační funkce, a můžete si vybrat jakoukoli metodu, která vám poskytne nejlepší výsledky. Jen musíte mít na paměti, že každá metoda počítá chyby jinak. U Arctanu bude chyba téměř vždy větší, protože funguje na principu: čím větší rozdíl, tím větší chyba. Kořenový MSE bude mít nejmenší chybu, takže je nejběžnější používat MSE, který udržuje rovnováhu při výpočtu chyb.

Kořenový MSE


Princip výpočtu chyb je ve všech případech stejný. Pro každou sadu počítáme chybu odečtením výsledku od ideální odpovědi. Dále jej buď odmocníme, nebo z tohoto rozdílu vypočítáme druhou mocninu, načež výsledné číslo vydělíme počtem množin.
Úkol
Nyní, abyste se otestovali, spočítejte výstup dané neuronové sítě pomocí sigmoidu a její chybu pomocí MSE.

Řešení
H1vstup = 1*0,45+0*-0,12=0,45
H1výstup = sigmoid(0,45)=0,61H2vstup = 1*0,78+0*0,13=0,78
Výstup H2 = sigmoid (0,78) = 0,69
O1ideální = 1 (0xor1=1)
Chyba = ((1-0,33)^2)/1=0,45
Velmi děkuji za Vaši pozornost! Doufám, že vám tento článek pomohl při studiu neuronových sítí. V příštím článku budu mluvit o bias neuronech a o tom, jak trénovat neuronovou síť pomocí backpropagation a gradientního sestupu.
Co je to posunový neuron?

Než začneme s naším hlavním tématem, musíme si představit koncept dalšího typu neuronu – posunového neuronu. Neuron posunutí nebo neuron zkreslení je třetím typem neuronu používaným ve většině neuronových sítí. Zvláštností tohoto typu neuronů je, že jeho vstup a výstup jsou vždy rovny 1 a nikdy nemají vstupní synapse. Vytěsňovací neurony mohou být buď přítomny v neuronové síti po jednom na vrstvu, nebo zcela nepřítomné; nemůže to být 50/50 (červeně v diagramu jsou váhy a neurony, které nelze umístit). Spojení zkreslených neuronů jsou stejná jako u běžných neuronů – se všemi neurony další úrovně, kromě toho, že mezi dvěma zkreslenými neurony nemohou být synapse. V důsledku toho mohou být umístěny na vstupní vrstvě a všech skrytých vrstvách, ale ne na výstupní vrstvě, protože prostě nebudou mít nic, s čím by se spojily.
K čemu slouží posunovací neuron?

Aby bylo možné získat výstupní výsledek posunutím grafu aktivační funkce doprava nebo doleva, je zapotřebí neuron posunutí. Pokud to zní zmateně, podívejme se na jednoduchý příklad, kde je jeden vstupní neuron a jeden výstupní neuron. Potom můžeme stanovit, že výstup O2 bude roven vstupu H1, vynásobený jeho hmotností a projde aktivační funkcí (vzorec na fotografii vlevo). V našem konkrétním případě použijeme sigmoid.
Ze školního kurzu matematiky víme, že pokud vezmeme funkci y = ax+b a změníme v ní hodnoty „a“, změní se sklon funkce (barvy čar v grafu na doleva), a pokud změníme „b“, posuneme funkci doprava nebo doleva (barvy čar na grafu vpravo). Takže „a“ je váha H1 a „b“ je váha zkreslení neuronu B1. Toto je hrubý příklad, ale v podstatě to tak funguje (pokud se podíváte na aktivační funkci vpravo na obrázku, všimnete si velmi silné podobnosti mezi vzorci). To znamená, že když během tréninku upravujeme váhy skrytých a výstupních neuronů, měníme sklon aktivační funkce. Úprava váhy zkreslených neuronů nám však může dát příležitost posunout aktivační funkci podél osy X a zachytit nové oblasti. Jinými slovy, pokud je bod zodpovědný za vaše řešení umístěn tak, jak je znázorněno v grafu vlevo, vaše neuronová síť nebude nikdy schopna vyřešit problém bez použití zkreslených neuronů. Proto jen zřídka uvidíte neuronové sítě bez zkreslených neuronů.
Vytěsňovací neurony také pomáhají v případě, kdy všechny vstupní neurony obdrží jako vstup 0 a bez ohledu na to, jakou váhu mají, všechny přejdou 0 do další vrstvy, ale ne v případě přítomnosti vytěsněného neuronu. Přítomnost nebo nepřítomnost zkreslených neuronů je hyperparametr (o tom později). Stručně řečeno, musíte se sami rozhodnout, zda potřebujete použít zkreslené neurony nebo ne, spuštěním NN s a bez zkreslení neuronů a porovnáním výsledků.
DŮLEŽITÉ Uvědomte si, že někdy posunutí neuronů není uvedeno na diagramech, ale jejich váhy jsou jednoduše brány v úvahu při výpočtu vstupní hodnoty, například:
vstup = H1*w1+H2*w2+b3
b3 = zkreslení*w3
Protože jeho výstup je vždy roven 1, můžeme si jednoduše představit, že máme další synapsi s váhou a tuto váhu přičteme k součtu, aniž bychom zmínili samotný neuron.
Jak přimět NS, aby odpovídaly správně?
Odpověď je jednoduchá – musíte ji vycvičit. Bez ohledu na to, jak jednoduchá je odpověď, její implementace z hlediska jednoduchosti ponechává mnoho přání. Existuje několik metod pro výuku neuronových sítí a já zdůrazním 3, podle mého názoru, nejzajímavější:
- Metoda zpětného šíření
- Odolné šíření nebo metoda Rprop
- Genetický algoritmus
Rprop a GA budou probrány v jiných článcích, ale nyní se podíváme na základ základů - metodu backpropagation, která využívá algoritmus gradientního sestupu.
Co je to gradientní klesání?
Toto je způsob, jak najít lokální minimum nebo maximum funkce pohybem po gradientu. Pokud rozumíte konceptu sestupu gradientu, neměli byste mít žádné otázky při použití metody backpropagation. Nejprve zjistíme, co je gradient a kde se v naší neuronové síti nachází. Vytvořme graf, kde na ose x budou hodnoty hmotnosti neuronu (w) a na ose y bude chyba odpovídající této váze (e).

Při pohledu na tento graf pochopíme, že graf funkce f(w) je závislost chyby na zvolené váze. V tomto grafu nás zajímá globální minimum – bod (w2,e2) nebo jinými slovy místo, kde se graf nejvíce přibližuje k ose x. Tento bod bude znamenat, že volbou váhy w2 dostaneme nejmenší chybu - e2 a v důsledku toho nejlepší výsledek ze všech možných. Tento bod nám pomůže najít metoda gradientního klesání (spád je na grafu vyznačen žlutě). Podle toho bude mít každá váha v neuronové síti svůj graf a gradient a pro každou je nutné najít globální minimum.
Co je tedy tento gradient? Gradient je vektor, který určuje strmost svahu a ukazuje jeho směr vzhledem k jakémukoli bodu na povrchu nebo grafu. Chcete-li najít gradient, musíte vzít derivaci grafu v daném bodě (jak je znázorněno v grafu). Pohybem ve směru tohoto sklonu plynule sklouzneme do údolí. Nyní si představte, že chyba je lyžař a graf funkce je hora. Pokud je tedy chyba 100 %, pak je lyžař na samém vrcholu hory, a pokud je chyba 0 %, pak na dně. Jako všichni lyžaři se chyba snaží co nejrychleji sjet dolů a snížit svou hodnotu. Nakonec bychom měli dostat následující výsledek:

Představte si, že lyžař je vyhozen pomocí vrtulníku na horu. Jak vysoká nebo nízká závisí na velikosti písmen (podobně jako v neuronové síti jsou při inicializaci váhy umístěny v náhodném pořadí). Řekněme, že chyba je 90 % a toto je náš výchozí bod. Nyní musí lyžař sjet dolů pomocí stoupání. Cestou dolů si v každém bodě spočítáme gradient, který nám ukáže směr klesání a při změně sklonu jej opravíme. Pokud je svah rovný, tak po n-tém počtu takových akcí dojedeme do nížiny. Ale ve většině případů bude svah (graf funkcí) zvlněný a náš lyžař bude čelit velmi vážnému problému - lokálnímu minimu. Myslím, že každý ví, co je lokální a globální minimum funkce, pro osvěžení paměti je příklad. Dostat se do místního minima je plné skutečnosti, že náš lyžař navždy zůstane v této nížině a nikdy se nesvalí z hory, a proto nikdy nebudeme schopni získat správnou odpověď. Tomu se ale můžeme vyhnout tím, že svého lyžaře vybavíme jetpackem zvaným momentum. Zde je stručná ilustrace tohoto okamžiku:

Jak už asi tušíte, tento batoh dodá lyžaři potřebné zrychlení k překonání kopce, který nás drží v místním minimu, ale je tu jedno ALE. Představme si, že jsme nastavili určitou hodnotu parametru moment a dokázali snadno překonat všechna lokální minima a dosáhnout globálního minima. Protože nemůžeme jetpack jednoduše vypnout, můžeme globální minimum přeskočit, pokud jsou v jeho blízkosti stále nízké hodnoty. V konečném případě to není tak důležité, protože dříve nebo později se stejně vrátíme zpět ke globálnímu minimu, ale je třeba si uvědomit, že čím větší moment, tím větší rozsah, se kterým bude lyžař lyžovat v nížinách. Spolu s momentem metoda backpropagation používá také takový parametr, jako je rychlost učení. Jak si asi mnozí budou myslet, čím vyšší rychlost učení, tím rychleji budeme trénovat neuronovou síť. Ne. Rychlost učení, stejně jako točivý moment, je hyperparametr – hodnota, která se vybírá metodou pokusů a omylů. Rychlost učení může přímo souviset s rychlostí lyžaře a můžeme s jistotou říci, že čím dále půjdete, tím tišeji půjdete. Jsou zde však i určité aspekty, protože pokud lyžaři neudělíme vůbec žádnou rychlost, nepojede vůbec nikam, a pokud mu dáme nízkou rychlost, tak se doba jízdy může protáhnout na velmi , velmi dlouhá doba. Co se stane, když dáme příliš velkou rychlost?

Jak vidíte, nic dobrého. Lyžař začne klouzat po špatné cestě a možná i opačným směrem, což nás, jak jistě chápete, jen vzdálí od nalezení správné odpovědi. Ve všech těchto parametrech je proto nutné najít zlatou střední cestu, abychom se vyhnuli nekonvergenci NS (o tom o něco později).
Co je metoda zpětné propagace (BPM)?
Nyní jsme se dostali do bodu, kdy můžeme diskutovat o tom, jak zajistit, aby se váš NS mohl správně učit a přijímat správná rozhodnutí. MPA je v tomto GIFu velmi dobře vizualizován:

Nyní se podívejme na každou fázi podrobně. Pokud si vzpomínáte, v předchozím článku jsme počítali výkon NS. Jiným způsobem se tomu říká dopředný průchod, to znamená, že postupně přenášíme informace ze vstupních neuronů na výstupní neurony. Poté vypočítáme chybu a na jejím základě provedeme zpětný přenos, který spočívá v postupné změně vah neuronové sítě, počínaje vahami výstupního neuronu. Hodnota vah se bude měnit směrem, který nám poskytne nejlepší výsledek. Ve svých výpočtech použiji metodu nalezení delty, protože je to nejjednodušší a nejsrozumitelnější metoda. Pro aktualizaci vah použiji také stochastickou metodu (o tom později).
Nyní pokračujme tam, kde jsme skončili s výpočty v předchozím článku.
Údaje o úkolu z předchozího článku
Data: I1=1, I2=0, w1=0,45, w2=0,78, w3=-0,12, w4=0,13, w5=1,5, w6=-2,3.
H1vstup = 1*0,45+0*-0,12=0,45
Výstup H1 = sigmoid(0,45)=0,61
H2vstup = 1*0,78+0*0,13=0,78
Výstup H2 = sigmoid (0,78) = 0,69
O1vstup = 0,61*1,5+0,69*-2,3=-0,672
Výstup O1 = sigmoid(-0,672)=0,33
O1ideální = 1 (0xor1=1)
Chyba = ((1-0,33)^2)/1=0,45
Výsledek – 0,33, chyba – 45 %.
Protože jsme již vypočítali výsledek NN a jeho chybu, můžeme rovnou přistoupit k MOR. Jak jsem již zmínil dříve, algoritmus vždy začíná výstupním neuronem. V tomto případě pro něj vypočítejme hodnotu δ (delta) pomocí vzorce 1.  Protože výstupní neuron nemá odchozí synapse, použijeme první vzorec (δ výstup), proto pro skryté neurony již použijeme druhý vzorec (δ skrytý). Vše je zde celkem jednoduché: vypočítáme rozdíl mezi požadovaným a získaným výsledkem a vynásobíme ho derivací aktivační funkce ze vstupní hodnoty daného neuronu. Než začneme s výpočty, chci vás upozornit na derivaci. Za prvé, jak se již pravděpodobně ukázalo, u MOR je nutné používat pouze ty aktivační funkce, které lze odlišit. Za druhé, aby se předešlo zbytečným výpočtům, může být odvozený vzorec nahrazen přátelštějším a jednodušším vzorcem formuláře:
Protože výstupní neuron nemá odchozí synapse, použijeme první vzorec (δ výstup), proto pro skryté neurony již použijeme druhý vzorec (δ skrytý). Vše je zde celkem jednoduché: vypočítáme rozdíl mezi požadovaným a získaným výsledkem a vynásobíme ho derivací aktivační funkce ze vstupní hodnoty daného neuronu. Než začneme s výpočty, chci vás upozornit na derivaci. Za prvé, jak se již pravděpodobně ukázalo, u MOR je nutné používat pouze ty aktivační funkce, které lze odlišit. Za druhé, aby se předešlo zbytečným výpočtům, může být odvozený vzorec nahrazen přátelštějším a jednodušším vzorcem formuláře: 
Naše výpočty pro bod O1 tedy budou vypadat takto.
Řešení
Tím jsou výpočty pro neuron O1 dokončeny. Pamatujte, že po výpočtu delta neuronu musíme okamžitě aktualizovat váhy všech odchozích synapsí tohoto neuronu. Protože v případě O1 žádné nejsou, přejdeme na neurony skryté úrovně a uděláme to samé, až na to, že nyní máme druhý vzorec pro výpočet delty a jeho podstatou je vynásobit derivaci aktivační funkce. ze vstupní hodnoty součtem součinů všech odchozích vah a delta neuronu, se kterým je tato synapse spojena. Proč se ale vzorce liší? Faktem je, že celý smysl MOR je rozložit chybu výstupních neuronů na všechny váhy NN. Chybu lze vypočítat pouze na výstupní úrovni, jak jsme již provedli, vypočítali jsme také deltu, ve které již tato chyba existuje. Nyní tedy místo chyby použijeme deltu, která se bude přenášet z neuronu na neuron. V tomto případě najdeme deltu pro H1:
Řešení
Výstup H1 = 0,61
w5 = 1,5
δO1 = 0,148δH1 = ((1 - 0,61) * 0,61) * (1,5 * 0,148) = 0,053
Nyní musíme najít gradient pro každou odchozí synapsi. Sem obvykle vkládají třípatrový zlomek s hromadou derivací a další matematické peklo, ale v tom je krása použití metody delta počítání, protože nakonec váš vzorec pro nalezení gradientu bude vypadat takto:
Zde bod A je bod na začátku synapse a bod B je na konci synapse. Takže můžeme vypočítat gradient w5 takto:
Řešení
Nyní máme všechna potřebná data k aktualizaci váhy w5 a uděláme to díky funkci MOP, která vypočítá množství, o které je třeba tu či onu váhu změnit a vypadá to takto: 
Důrazně doporučuji neignorovat druhou část výrazu a používat moment, protože to vám umožní vyhnout se problémům s místním minimem.
Zde vidíme 2 konstanty, o kterých jsme již mluvili, když jsme se podívali na algoritmus sestupu gradientu: E (epsilon) je rychlost učení, α (alfa) je moment. Převedeme-li vzorec do slov, dostaneme: změna váhy synapse se rovná koeficientu rychlosti učení vynásobenému gradientem této váhy, přidáme moment vynásobený předchozí změnou této váhy (při 1. iteraci je 0). V tomto případě vypočítejme změnu hmotnosti w5 a aktualizujeme její hodnotu přidáním Δw5.
Řešení
Po aplikaci algoritmu se tedy naše váha zvýšila o 0,063. Nyní navrhuji, abyste udělali totéž pro H2.
Řešení
A samozřejmě nezapomeňte na I1 a I2, protože také mají synapse, jejichž váhy také musíme aktualizovat. Pamatujte však, že pro vstupní neurony nepotřebujeme hledat delty, protože nemají vstupní synapse.
Řešení
Nyní se přesvědčme, že jsme vše provedli správně a opět počítejme výstup neuronové sítě pouze s aktualizovanými vahami.
Řešení
Jak můžeme vidět po jedné iteraci MOP, podařilo se nám snížit chybu o 0,04 (6 %). Nyní to musíte opakovat znovu a znovu, dokud vaše chyba nebude dostatečně malá.
Co dalšího potřebujete vědět o procesu učení?
Neuronovou síť lze trénovat s učitelem nebo bez něj (učení pod dohledem, bez dozoru).
Doučovaný výcvik- toto je typ tréninku, který je vlastní takovým problémům, jako je regrese a klasifikace (použili jsme jej ve výše uvedeném příkladu). Jinými slovy, zde vystupujete jako učitel a NS jako student. Zadáte vstupní data a požadovaný výsledek, to znamená, že student při pohledu na vstupní data pochopí, že se musí snažit o výsledek, který jste mu poskytli.
Učení bez dozoru- tento typ školení se nevyskytuje příliš často. Není zde žádný učitel, takže síť nedosahuje požadovaného výsledku nebo je jich velmi malý počet. V zásadě je tento typ tréninku vlastní neuronovým sítím, jejichž úkolem je seskupovat data podle určitých parametrů. Řekněme, že odešlete 10 000 článků o Habrém a po analýze všech těchto článků je NS bude moci rozdělit do kategorií založených například na často se vyskytujících slovech. Články, které zmiňují programovací jazyky, programování a kde jsou slova jako Photoshop, design.
Existuje také taková zajímavá metoda jako posilovací učení(posilovací učení). Tato metoda si zaslouží samostatný článek, ale pokusím se stručně popsat její podstatu. Tato metoda je použitelná, pokud ji můžeme na základě výsledků získaných z NS posoudit. Například chceme naučit NS hrát PAC-MAN, pak pokaždé, když NS získá hodně bodů, budeme ji povzbuzovat. Jinými slovy, dáváme NS právo najít jakýkoli způsob, jak dosáhnout cíle, pokud poskytuje dobrý výsledek. Síť tak začíná chápat, čeho z ní chce dosáhnout, a snaží se najít nejlepší způsob, jak tohoto cíle dosáhnout, aniž by neustále poskytovala data od „učitele“.
Školení lze také provádět třemi metodami: stochastickou metodou, dávkovou metodou a minidávkovou metodou. Existuje tolik článků a studií o tom, která metoda je nejlepší, a nikdo nemůže přijít na obecnou odpověď. Jsem zastáncem stochastické metody, ale nepopírám, že každá metoda má svá pro a proti.
Krátce o každé metodě:
Stochastické(někdy se jí také říká online) metoda funguje na následujícím principu - najděte Δw, okamžitě aktualizujte odpovídající váhu.
Dávková metoda funguje to jinak. Sečteme Δw všech vah v aktuální iteraci a teprve poté aktualizujeme všechny váhy pomocí tohoto součtu. Jednou z nejdůležitějších výhod tohoto přístupu je značná úspora času výpočtu, ale přesnost v tomto případě může být značně ovlivněna.
Mini-dávková metoda je zlatou střední cestou a snaží se spojit výhody obou metod. Princip je zde tento: váhy volně rozdělujeme mezi skupiny a měníme jejich váhy o součet Δw všech vah v konkrétní skupině.
Co jsou hyperparametry?
Hyperparametry jsou hodnoty, které je nutné vybrat ručně a často metodou pokusu a omylu. Mezi tyto hodnoty patří:
- Okamžik a rychlost učení
- Počet skrytých vrstev
- Počet neuronů v každé vrstvě
- Přítomnost nebo nepřítomnost posunovacích neuronů
Jiné typy neuronových sítí obsahují další hyperparametry, ale o těch se bavit nebudeme. Výběr správných hyperparametrů je velmi důležitý a přímo ovlivní konvergenci vašeho NN. Je docela jednoduché pochopit, zda stojí za to používat posunovací neurony nebo ne. Počet skrytých vrstev a neuronů v nich lze spočítat hrubou silou na základě jednoho jednoduchého pravidla – čím více neuronů, tím přesnější výsledek a exponenciálně delší čas, který strávíte jeho tréninkem. Je však třeba si uvědomit, že byste neměli vytvářet neuronové sítě s 1000 neurony k řešení jednoduchých problémů. Jenže s volbou okamžiku a rychlostí učení je vše trochu složitější. Tyto hyperparametry se budou lišit v závislosti na aktuální úloze a architektuře neuronové sítě. Například pro řešení XOR může být rychlost učení v rozmezí 0,3 - 0,7, ale v neuronové síti, která analyzuje a předpovídá ceny akcií, vede rychlost učení nad 0,00001 ke špatné konvergenci neuronové sítě. Neměli byste nyní zaměřovat svou pozornost na hyperparametry a snažit se důkladně pochopit, jak je vybrat. To přijde se zkušenostmi, ale prozatím vám doporučuji jednoduše experimentovat a hledat příklady řešení konkrétního problému na internetu.
Co je to konvergence?

Konvergence udává, zda je architektura NN správná a zda byly hyperparametry vybrány správně v souladu s úlohou. Řekněme, že náš program zobrazuje chybu NS při každé iteraci v protokolu. Pokud se chyba s každou iterací snižuje, pak jsme na správné cestě a naše NN konverguje. Pokud chyba skáče nahoru a dolů nebo zamrzne na určité úrovni, pak NN nekonverguje. V 99% případů se to řeší změnou hyperparametrů. Zbývající 1 % bude znamenat, že máte chybu v architektuře neuronové sítě. Stává se také, že konvergence je ovlivněna přetrénováním neuronové sítě.
Co je to rekvalifikace?
Overfitting, jak název napovídá, je stav neuronové sítě, kdy je přesycena daty. K tomuto problému dochází, pokud trénujete síť na stejných datech příliš dlouho. Jinými slovy, síť se začne neučit z dat, ale zapamatovat si je a „nacpat“. V souladu s tím, když odešlete nová data na vstup této neuronové sítě, může se v přijatých datech objevit šum, který ovlivní přesnost výsledku. Pokud například ukážeme NS různé fotografie jablek (pouze červená) a řekneme, že toto je jablko. Když pak NN uvidí žluté nebo zelené jablko, nebude schopna určit, že je to jablko, protože si vzpomněla, že všechna jablka musí být červená. A naopak, když NN uvidí něco červeného a ve tvaru jablka, například broskev, řekne, že je to jablko. Tohle je hluk. Na grafu bude šum vypadat takto.

Je vidět, že graf funkce velmi kolísá z bodu do bodu, což jsou výstupní data (výsledek) našeho NN. V ideálním případě by tento graf měl být méně zvlněný a rovný. Aby nedošlo k přetrénování, neměli byste neuronovou síť trénovat dlouhodobě na stejných nebo velmi podobných datech. Také přefitování může být způsobeno velkým množstvím parametrů, které dodáváte na vstup neuronové sítě nebo příliš složitou architekturou. Když tedy po tréninkové fázi zaznamenáte chyby (šum) ve výstupu, měli byste použít některou z metod regularizace, ale ve většině případů to nebude nutné.



